How AI Automates Test Data Validation



AI-powered test data validation simplifies and accelerates the process of ensuring data accuracy, consistency, reliability, and integrity. By automating manual tasks, detecting anomalies, and continuously monitoring data, AI reduces errors, saves time, and improves overall data quality and QA metrics.
Key insights:
- AI replaces manual validation by learning patterns and spotting irregularities in real-time.
- It ensures data consistency across systems and integrity during transformations.
- Steps include: defining validation rules, anomaly detection, source-to-target checks, and continuous monitoring.
- Real-world examples highlight how AI prevents costly errors, like Zillow's $500M loss in 2021.
Why it matters: AI validation handles large datasets quickly, reduces costs, and minimizes human error, making it essential for modern QA processes.
Steps to Automate Test Data Validation with AI
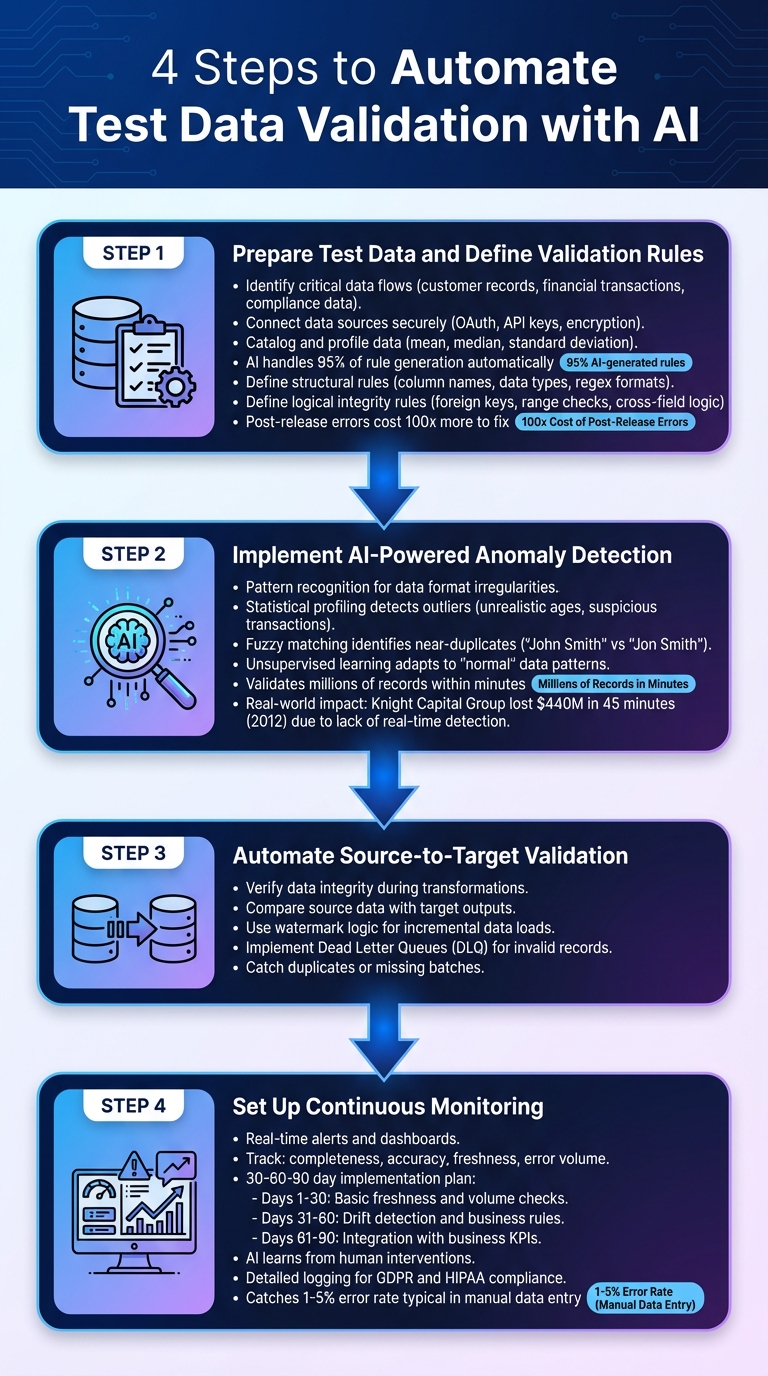
4-Step AI-Powered Test Data Validation Process
Step 1: Prepare Test Data and Define Validation Rules
Start by identifying the critical data flows you need to monitor, such as customer records, financial transactions, or compliance-related data. Securely connect your data sources using methods like OAuth tokens or API keys, and make sure data is encrypted both during transit and when stored.
Next, catalog and profile your data using statistical techniques like calculating the mean, median, and standard deviation. This helps establish baselines for validation rules. Automated tools can handle as much as 95% of rule generation, cutting down on manual effort. For the remaining 5%, define specific structural rules (like column names, data types, and format validation using regex) and logical integrity rules (such as foreign keys, range checks, and cross-field logic).
Document everything in a structured framework. This includes acceptable ranges, required formats, and business logic. Such documentation ensures uniformity across systems and helps avoid costly post-release errors, which can be 100 times more expensive to fix.
Once your baseline rules are in place, you’re ready to bring in AI for real-time anomaly detection.
Step 2: Implement AI-Powered Anomaly Detection
AI tools excel at pattern recognition, making them ideal for spotting irregularities in data formats. For example, they can flag inconsistencies like incorrect phone number structures or unusual address formats. By using statistical profiling, AI can also detect significant outliers, such as unrealistic ages or suspiciously large transaction amounts.
Another powerful feature is fuzzy matching, which identifies near-duplicates (e.g., "John Smith" vs. "Jon Smith") - a common issue during database merges or cleaning efforts. AI systems leverage unsupervised learning to adapt to what "normal" data looks like over time, reducing the need for constant manual updates to validation rules.
The speed of AI is a game-changer. It can validate millions of records within minutes. Consider the 2012 Knight Capital Group incident, where a software error caused $440 million in losses in just 45 minutes due to faulty stock trades - a disaster that real-time anomaly detection could have averted.
Step 3: Automate Source-to-Target Validation
After ensuring data consistency, the next step is verifying data integrity during transformations. Source-to-target validation ensures that joins, aggregations, and field mappings produce accurate results by directly comparing source data with target outputs.
For incremental data loads, use watermark logic to validate new records. This involves comparing timestamps to ensure that only expected new entries are included, catching duplicates or missing batches. In streaming environments, implement Dead Letter Queues (DLQ) to isolate invalid records for further investigation and replay.
Step 4: Set Up Continuous Monitoring
With validation rules, anomaly detection, and source-to-target checks in place, the final step is continuous monitoring to maintain data integrity over time.
Set up real-time alerts and dashboards to track key metrics like completeness, accuracy, freshness, and error volume. A 30-60-90 day implementation plan can help you phase in functionality: start with basic freshness and volume checks in the first 30 days, add drift detection and business rules by day 60, and integrate with business KPIs by day 90. Feedback loops allow the AI system to learn from human interventions, reducing future false positives.
Keep detailed logs of every validation event to meet compliance requirements for regulations like GDPR and HIPAA.
"What used to be weeks, now takes minutes!" - Jennifer Leidich, Co-Founder & CEO, Mercury
To detect silent failures or stale data, monitor changes in record counts (volumetric changes) and update timestamps (freshness). This approach catches the 1% to 5% error rate typical in manual data entry before it snowballs across your systems.
sbb-itb-7ae2cb2
Integrating AI Validation into QA Workflows
Using Ranger for End-to-End Testing
Ranger seamlessly connects AI-powered test data validation with practical QA workflows by embedding directly into your development pipeline. It works with tools like GitHub and Slack to automatically run test suites in CI/CD pipelines as code changes, share results within pull requests, and notify team members in real time.
The platform handles its own hosted infrastructure, launching browsers to perform consistent tests without requiring internal maintenance. This eliminates the hassle of managing test environments and ensures tests are conducted on staging and preview setups, catching bugs before they hit production.
Ranger takes a hybrid approach - AI generates initial tests while QA experts review the code to ensure reliability. Automated triage filters out noisy or flaky tests, enabling engineering teams to focus on genuine bugs and critical issues.
"Ranger has an innovative approach to testing that allows our team to get the benefits of E2E testing with a fraction of the effort they usually require." – Brandon Goren, Software Engineer at Clay.
Developers can use the Ranger CLI (ranger go) to walk through user flows while capturing screenshots and video recordings. Once a feature is verified during the review process, it can be converted into a permanent end-to-end test with just one click.
This integration of AI-driven validation into daily QA processes showcases how AI can reshape test data management.
Improving Team Collaboration and Reporting
In addition to its seamless integration, Ranger enhances teamwork and reporting, boosting overall QA efficiency. The platform's Feature Review Dashboard mirrors GitHub pull request reviews but is tailored for UI features. It provides browser-based evidence like screenshots, video recordings, and Playwright traces, allowing teams to collaboratively approve features, leave comments, or request changes. This fosters better communication and alignment between developers and QA teams.
For teams using AI coding tools like Claude or Cursor, Ranger acts as a verification layer. It ensures the AI agent iterates until a browser-based check confirms the feature works as intended. If the agent gets stuck, the platform facilitates human intervention to resolve issues.
"I definitely feel more confident releasing more frequently now than I did before Ranger. Now things are pretty confident on having things go out same day once test flows have run." – Jonas Bauer, Co-Founder and Engineering Lead at Upside.
Benefits of AI-Automated Test Data Validation
Manual vs. AI Validation Comparison
AI-powered validation systems significantly outperform manual methods in both speed and accuracy. For instance, while manual checks often take hours or even days, AI can complete the same tasks in mere minutes - or even in real time. Error rates are also drastically reduced, with AI achieving just 30–50% of the error levels typically seen in manual production environments.
| Feature | Manual Validation | AI-Powered Validation |
|---|---|---|
| Speed | Slow (hours/days) | Fast (minutes/real time) |
| Scalability | Limited to small datasets | Handles millions of records |
| Error Detection | Prone to human oversight | Highly accurate; detects subtle anomalies |
| Resource Needs | Labor-intensive | Automated; minimal human input |
| Consistency | Variable/subjective | Consistent and repeatable |
| Audit Trail | Manual and error-prone | Automated and continuous |
| Cost | High due to labor hours | Lower through automation |
These differences lead to major savings in both time and costs, allowing engineering teams to focus on more complex challenges instead of repetitive tasks.
Reducing Time and Resource Costs
One of the standout advantages of AI validation is how it eliminates the need for manual, repetitive work. Engineers no longer have to spend hours creating and maintaining static validation rules. Instead, AI learns from the data itself, identifying what constitutes "normal" and automatically adjusting its rules over time. A great example is Siemens Healthineers, which processes 8 million messages daily using real-time AI validation. This approach has helped organizations reduce their data request backlogs by up to 80%.
AI also speeds up root cause analysis. By providing detailed incident timelines and pinpointing upstream issues - like a specific column change in a job - AI can diagnose problems in minutes that would otherwise take hours. This proactive bug detection prevents bad data from spreading through systems, saving teams from the time-intensive cleanup that often follows such incidents.
Improving Accuracy and Scalability
Beyond time and cost savings, AI brings unmatched precision and scalability to data validation. Unlike human reviewers, AI can spot patterns and anomalies that might otherwise go unnoticed. For example:
- Pattern Recognition: Flags irregularities like non-standard phone numbers.
- Outlier Detection: Identifies data points that deviate significantly, such as unrealistic ages or extreme values.
- Fuzzy Matching: Ensures data integrity by catching near-duplicate records (e.g., "John Smith" vs. "Jon Smith").
AI's ability to scale is a game-changer as datasets grow in size. Using distributed computing and statistical sampling, it can validate millions of records without bottlenecks. Additionally, employing consensus mechanisms - where multiple models work together - cuts error rates by 40–60% compared to relying on a single model. The global AI testing market, now valued at over $757 billion as of 2026, underscores the rapid adoption of these advanced methods.
Machine learning also creates feedback loops from human approvals, continuously improving validation accuracy without requiring constant manual adjustments or rule updates.
"It's not just about saving time and money, it's about making data accessible." – Enver Melih Sorkun, Co-founder & CTO, Growdash
Common Challenges in AI Test Data Validation
Managing Schema Drift and Data Changes
A recent six-month audit revealed that nearly half (49%) of endpoints experienced undocumented schema changes, costing teams up to seven engineering days each month. These issues often stem from manual production hotfixes, unintended changes in AI code, or updates to third-party APIs that alter response formats without prior notice. On average, resolving such incidents takes about 3.5 days.
AI systems can help by inferring schema baselines directly from data sources. They can distinguish harmless changes from critical ones and categorize the severity of schema drift, significantly reducing the need for manual intervention. This approach eliminates the hassle of manually updating JSON Schemas and flags unexpected shifts in data patterns.
"Schema drift is the silent, usually undocumented divergence between what an API is supposed to return and what it actually returns over time." – Tanvi Mittal, AI Quality Engineer
To stay ahead of schema drift, teams can adopt a "Schema as Code" strategy, explicitly defining expected schemas within CI/CD pipelines. The Expand/Contract pattern is another effective technique: introduce new fields, backfill data, update readers and writers, and eventually phase out outdated fields in a backward-compatible manner. AI tools that infer schemas from runtime data can also address the limitations of static, outdated specifications.
This proactive approach to schema management lays the groundwork for addressing the next challenge: alert accuracy.
Reducing False Positives and Negatives
Schema issues aside, maintaining a balance between false positives and false negatives is a constant struggle in AI validation systems. Even a small false positive rate - say, 1% - can overwhelm teams with alerts in high-volume environments. Tightening thresholds too much could result in missed genuine issues, while loosening them may lead to an avalanche of false alarms.
AI tackles this by analyzing data in context, correlating multiple signals rather than evaluating isolated data points. This results in fewer but more reliable detections. Machine learning feedback loops further refine the system. For instance, if human reviewers consistently approve flagged data as valid, the model adjusts its thresholds over time. Advanced models can even perform semantic checks, like verifying that a job title aligns with a company’s size or that a phone number’s area code matches its state.
Real-world examples highlight the impact of these techniques. One deployment improved rejection accuracy by 23% and reduced manual QA workload by 35% within 90 days. In another case, a credit union cut its total alert volume by 65% using an AI-driven platform, allowing analysts to focus on real threats.
To enhance accuracy even further, AI systems can categorize records into groups like "Auto-approved", "Review recommended", and "Rejected". Incorporating human reviewers into the process ensures that flagged entries provide valuable training data for monthly model updates. Additionally, active validation methods - such as pinging APIs to confirm flagged issues - boost confidence in predictions.
Optimizing Performance for Large Datasets
When dealing with billions of records daily, performance optimization becomes a necessity. Distributed execution and a mix of real-time test feedback and batch validation can improve performance by over 90%, focusing resources on the most critical data points. Inline validation tools like Apache Kafka or Flink catch errors during data ingestion, while batch frameworks such as Spark or Deequ perform more comprehensive checks across datasets.
Instead of striving for exhaustive test coverage, which can inflate test suites, focus validation efforts on critical data products and key pipeline stages. These include ingestion points, ETL/ELT layers, and pre-dashboard stages.
AI can also leverage metadata-aware rule generation, using schema metadata and business glossaries to create more accurate and efficient validation rules. Running these AI-generated rules in "shadow mode" - logging violations without affecting data flow - allows teams to fine-tune their systems before fully enforcing them in production. YAML-based abstractions within orchestration platforms can simplify the creation and management of thousands of data quality tests without requiring manual coding.
One company saw a 42% reduction in time-to-validation after deploying generative AI tools across its ETL pipelines, along with noticeable improvements in accuracy and workload efficiency within 90 days. By optimizing performance, AI validation systems remain effective even as data volumes grow, supporting agile QA processes at scale.
Conclusion
The Future of AI in Test Data Validation
AI-driven validation is evolving far beyond basic pass/fail checks. Tools now incorporate data observability to trace data lineage and pinpoint failures, making troubleshooting faster and more efficient. Generative AI is also stepping up, offering the ability to craft diverse test cases and create adaptable, self-healing scripts. On top of that, natural language interfaces are making it easier for non-technical users to query validated data using plain English instead of relying on SQL.
The numbers speak for themselves: with the global AI software market expected to hit $126 billion by 2025 and 38% of organizations adopting remote validation practices, AI is poised to revolutionize the way we approach test data validation. It’s not just about automation anymore - it’s about preventing errors before they happen, learning continuously from feedback, and scaling effortlessly alongside growing data volumes. Platforms like Ranger are perfectly positioned to lead this transformation in testing practices.
Why Choose AI-Powered Solutions Like Ranger
Ranger capitalizes on these advancements to offer practical, AI-powered automation combined with human oversight for a seamless, end-to-end testing experience. By integrating with tools like Slack and GitHub, Ranger automates the creation and upkeep of test cases while ensuring that genuine bugs are caught before they can affect end users. With its real-time testing signals and robust infrastructure, teams can release new features faster without compromising on quality.
The impact is clear. Individual analysts have reported saving 7 to 10 hours per week, and data teams have slashed their request backlogs by up to 80%. By adopting AI-powered solutions, QA teams can redirect their energy toward high-value tasks like exploratory testing and strategic initiatives, while intelligent systems handle routine validation and continually improve over time. It’s a smart choice for any team looking to streamline their processes and stay ahead in a data-driven world.
FAQs
What data should we validate first?
The first step in any testing or validation process is to ensure the input data meets the required standards. This means checking that the data is of the correct type - whether it's an integer, string, or Boolean. Beyond type, the data should also be accurate, consistent, and of high quality.
Why is this important? Validating input data early prevents errors from creeping into the process. It ensures that every subsequent step is based on reliable and trustworthy data, laying a solid foundation for accurate testing results. Skipping this step could lead to flawed outcomes, wasting time and resources.
How do we keep AI validation accurate as schemas change?
To keep AI validation accurate during schema updates, it's important to have a solid plan in place. Strategies such as version control, automated migration, and ensuring backward compatibility can make updates smoother and safer. Regular end-to-end validation is key to maintaining data integrity across databases, APIs, and configurations, helping to catch and prevent inconsistencies.
Additionally, implementing monitoring systems, thorough testing, and rollback processes can address potential problems quickly. These steps ensure that schema updates won't interfere with validation processes or create disruptions.
How can we reduce false alerts from anomaly detection?
AI-powered test data validation systems aim to cut down on false alerts by learning what "normal" data looks like and ignoring minor fluctuations. These tools rely on techniques like pattern recognition, outlier detection, and adaptive learning to focus only on anomalies that truly matter - such as unexpected spikes or significant outliers. By adding context-aware analysis into the mix, they can filter out routine variations, ensuring alerts remain relevant and reducing the noise of unnecessary notifications.
Related Blog Posts
Stop babysitting your coding agents. Use Ranger
More signals, less noise, faster launches
Let Ranger be your guide to sustainable QA testing.

.png)