How AI Improves Test Data Sync Accuracy


Test data synchronization is a critical issue for QA teams, often leading to flaky tests, delayed releases, and bugs in production. Traditional methods like manual data creation or cloning production data are slow, error-prone, and risk violating privacy regulations. AI-powered tools are solving these challenges by automating test data generation, detecting anomalies, and ensuring real-time validation across environments.
Key Insights:
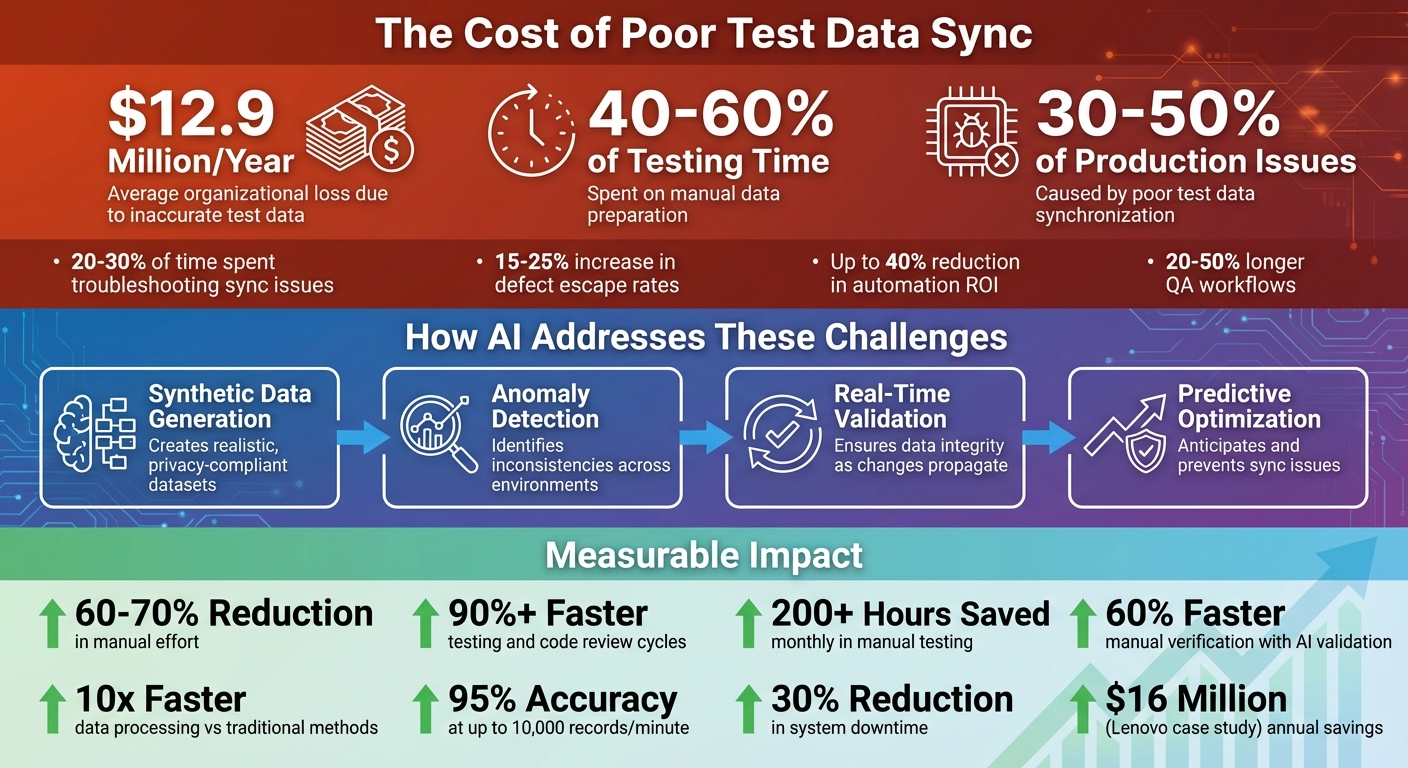
- $12.9 million/year: Average loss for organizations due to inaccurate test data.
- 40%-60% of testing time: Spent on manual data preparation, which AI reduces significantly.
- 30%-50% of production issues: Caused by poor test data synchronization.
How AI Solves These Problems:
- Synthetic Data Generation: Creates realistic, privacy-compliant datasets.
- Anomaly Detection: Identifies inconsistencies across environments.
- Real-Time Validation: Ensures data integrity as changes propagate.
- Predictive Optimization: Anticipates and prevents sync issues.
Results:
- Reduced manual effort by 60%-70%.
- Faster testing cycles, saving hundreds of hours monthly.
- Improved automation reliability, cutting flakiness and delays.
AI tools like Ranger integrate seamlessly with platforms like Slack and GitHub, providing real-time updates and proactive testing. By addressing synchronization challenges, AI helps QA teams deliver faster, more reliable releases while minimizing risks.
The Cost of Poor Test Data Synchronization: Key Statistics and AI Impact
How to Find Data in Multiple Systems Using AI | Enterprise Test Data
Common Problems in Test Data Synchronization
QA teams often navigate a labyrinth of challenges when trying to maintain consistent test data across multiple environments. A major hurdle is the diverse range of data sources and formats, which makes it nearly impossible to establish a unified source of truth. The rise of cloud-native architectures, with their web of independently evolving microservices, only adds to the complexity of synchronization.
Data Inconsistencies Across Environments
The disconnect between development, staging, and production environments leads to unreliable test results. For instance, data scientists frequently work with small, localized datasets that fail to behave predictably in distributed production systems, making it harder to predict bugs before they happen. One of the biggest culprits here is schema drift - when changes like new columns or altered data types occur in one environment but don’t propagate to others. This misalignment causes replication jobs to fail, creates data gaps, and breaks test scripts. The fast-paced evolution of fragmented microservices further complicates matters, breaking dependencies and destabilizing the entire testing pipeline. To address these discrepancies, teams often resort to manual synchronization, which is both time-consuming and prone to errors. This is why many teams are moving toward a fully-automated QA engineer approach to eliminate these manual bottlenecks.
Manual Processes and Human Error
Manual synchronization struggles to keep up with the speed of modern release cycles. In fact, preparing test data alone can consume 40% to 60% of the total testing time. Teams often spend days manually creating datasets in spreadsheets or copying production data - a process that frequently results in flawed test accounts, unrealistic datasets, and heightened security risks due to improper data masking.
A striking example comes from Salesforce's Agentforce Platform Testing team. In August 2025, they found that manually analyzing 700-page technical manuals for generating test scenarios took an exhausting 4.5 days. After adopting AI prompt engineering, this process was slashed to just 2 hours. Similarly, their manual voice testing workflows, which previously required three engineering days, were reduced to a mere hour - a staggering 1,000% improvement in test data creation efficiency.
Scaling Issues and Conflict Resolution
Large teams face even greater challenges when scaling tests. Concurrent modifications across services often lead to conflicts that require advanced strategies, like versioning or "last-write-wins" rules. Unfortunately, manual processes are ill-equipped to handle these conflicts in real time. Hybrid or multi-cloud setups add another layer of complexity, as network latency slows data transfers, and full data refreshes waste resources by unnecessarily moving unchanged records.
The urgency of these issues is further amplified by the growing demand for data to train AI and machine learning models - doubling every 18 months. These scaling challenges not only waste time and resources but also directly undermine the accuracy and reliability of testing efforts.
How Inaccurate Test Data Sync Affects QA Processes
Faulty test data synchronization can derail QA workflows, slowing down releases, compromising quality, and reducing efficiency. These problems amplify the synchronization challenges already discussed, making effective solutions a pressing need.
Flaky Tests and Pipeline Delays
Flaky tests - those automated tests that unpredictably pass or fail without any code changes - are a direct result of poor data synchronization. When test data doesn’t match across environments, tests behave inconsistently, often triggering false positives or negatives. For instance, a test designed to validate specific user data may fail if staging and production-like environments are out of sync, leading to unnecessary debugging sessions and wasted time.
Research indicates that teams spend 20%–30% of their time troubleshooting tests impacted by synchronization issues. In high-traffic systems, network inconsistencies or incomplete data syncs can cause intermittent failures, stalling automated CI/CD pipelines and delaying releases by hours or even days. Picture a smart city dashboard test failing sporadically due to lagging edge data - pipeline reruns might delay feature rollouts by one or two days per cycle.
More Bugs Reaching Production
When synchronization fails, QA teams are left testing with outdated or incomplete data, which means environment-specific bugs often go undetected until after deployment. This gap can increase defect escape rates by 15%–25%, leading to crashes or erratic behavior that frustrate users. Experts estimate that unreliable data synchronization is responsible for 30%–50% of production incidents caused by missed bugs.
Take conversational AI systems, for example. If batch sync delays occur during testing, chatbots may use outdated information, resulting in deployments with flawed responses. Similarly, a banking app might miss a transaction bug due to sync issues, leading to user-reported errors and a loss of trust. These scenarios highlight the risks of conflicting or incomplete data during testing.
Lower Automation Reliability
Data synchronization problems also undermine the reliability of automated testing frameworks. Automation thrives on consistent, accurate data to produce repeatable results. When data drifts, these frameworks yield inconsistent outcomes, forcing teams to rely more on manual verification. This shift can reduce automation’s return on investment by up to 40%. Flakiness rates exceeding 10%, uneven test coverage, and frequent manual overrides are clear signs of declining automation reliability.
As trust in automation drops, QA workflows and release timelines can stretch by 20%–50%, with teams spending extra time on manual checks. Flaky automation can also lead to batch reruns or reduced test scopes, leaving critical issues undetected. Without real-time data validation, even the most advanced testing frameworks can turn into bottlenecks, slowing delivery and increasing risks.
AI-Powered Solutions for Test Data Synchronization
AI has transformed test data synchronization by automating processes that address inconsistencies, conflicts, and performance issues. It also predicts and prevents potential disruptions, streamlining QA workflows.
Anomaly Detection and Data Integrity
AI models excel at detecting anomalies and maintaining data integrity. Using cross-database "data diffing", these systems automatically compare values between source and target databases, catching discrepancies that manual testing might overlook. Organizations adopting this approach have seen testing and code review cycles speed up by over 90%, saving more than 200 hours of manual testing each month.
Active Learning plays a key role here, identifying uncertain data points and involving human input to refine accuracy. Sensitivity analysis adds another layer by varying input features to detect bias and anomalies, ensuring consistent data integrity across environments. This is crucial, as 85% of AI projects are expected to fail due to insufficient data volume or poor data quality.
"Datafold helps you find the hidden changes you didn't know you made to your data, helping you if they're unintended or understanding what's causing them." - Zachary Baustein, Lead Product Analyst
With data integrity as a foundation, AI further strengthens synchronization through real-time validation and conflict resolution.
Real-Time Validation and Conflict Resolution
After spotting anomalies, AI ensures immediate validation and resolves conflicts seamlessly. Machine learning algorithms validate data instantly as changes propagate across systems. AI-powered platforms act as centralized hubs, pulling data from tools like CRMs, analytics platforms, and development environments. They automate updates to ensure consistency across environments.
When simultaneous updates lead to conflicts, AI agents use strategies such as "last-write-wins" or versioning to merge changes effectively. For instance, Lenovo reported annual savings of $16 million by implementing AI-driven workflow automation for data synchronization. Additionally, AI validation reduces manual verification time by 60% and processes data 10 times faster than traditional methods. These systems can handle up to 10,000 records per minute with 95% accuracy.
Predictive Optimization for Sync Performance
AI doesn't just fix current issues - it anticipates future ones. By analyzing historical patterns, AI predicts where synchronization lags might occur and suggests preemptive solutions. This continuous learning approach improves correction and optimization strategies over time, based on past validation tasks. Predictive modeling also intelligently estimates missing values, ensuring complete datasets across testing environments.
AI observability tools assist teams in forecasting synchronization performance and costs by pinpointing bottlenecks and optimizing resource use. The results are impactful: predictive analytics and real-time error detection can cut system downtime by up to 30%. Companies leveraging AI report 30% better decision accuracy and see revenue growth of 20%, while automating data cleaning and standardization reduces manual preparation by as much as 50%.
sbb-itb-7ae2cb2
How Ranger Improves Test Data Sync Accuracy
Ranger tackles the challenges of test data synchronization by combining the precision of AI with human expertise. Using a web agent, the platform navigates applications and builds Playwright tests that adapt to UI changes. This approach addresses the fragility of manual test scripts, ensuring that automation stays effective even as interfaces evolve.
AI-Driven Test Creation and Maintenance
Ranger’s method blends AI-generated efficiency with human oversight. AI agents create the initial test scripts, which are then reviewed by QA experts to ensure they are clear, reliable, and robust. As products change, these tests update automatically to reflect the latest data synchronization needs. Automated triaging also filters out flaky tests and reduces environmental noise, allowing teams to focus on the most critical issues.
"Ranger's approach delivers end-to-end testing benefits with a fraction of the effort they usually require." – Brandon Goren, Software Engineer, Clay
In February 2025, Ranger partnered with OpenAI to develop a web browsing harness for the o3-mini research paper. This collaboration showcased Ranger’s ability to track agentic behavior across diverse interfaces.
Real-Time Testing Signals and Hosted Infrastructure
Ranger simplifies testing infrastructure by managing it entirely on its platform. Browsers are launched to run consistent tests, which minimizes synchronization errors. This real-time testing ensures environments stay aligned, complementing Ranger’s proactive test creation. Unlike batch synchronization - which can leave test data outdated between updates - Ranger continuously tests staging and preview environments to detect inconsistencies and bugs before they hit production.
Jonas Bauer, Co-Founder and Engineering Lead at Upside, shared how Ranger transformed their workflow: “Implementing Ranger enabled our team to release code more frequently with the confidence to go live on the same day once test flows had run.”
Integration with Development Tools
Ranger extends its reliability by seamlessly integrating with tools like Slack and GitHub. Slack integration provides real-time updates on test results and data sync status, keeping teams informed. Meanwhile, GitHub integration embeds test results directly into the development process, helping catch synchronization issues before code merges.
"We are always adding new features, and Ranger has them covered in the blink of an eye." – Martin Camacho, Co-Founder, Suno
Best Practices for Implementing AI-Powered Test Data Sync
AI's ability to detect anomalies and validate data in real-time is a game-changer for test data synchronization. But to make the most of these capabilities, software teams need to go beyond simply adopting new tools. It's about rethinking infrastructure, setting clear performance goals, and testing systems under challenging, real-world scenarios.
Use Event-Driven Architectures
Event-driven architectures allow data changes to be propagated in real-time. This approach minimizes delays and quickly resolves conflicts whenever updates occur, ensuring smoother and more reliable synchronization.
Monitor Key Metrics for Sync Performance
Tracking the right metrics helps evaluate how well AI-powered synchronization is working. Here are some metrics to keep an eye on:
- Sync lag time: Measures how quickly changes are reflected across different environments. With AI automation, what used to take days can now be done in minutes.
- Error rates: Tracks how often synchronization fails or produces inconsistent data.
- Data coverage metrics: Evaluates how well test datasets reflect production data, covering edge cases and diverse data combinations. Gaps in data quality aren't just a technical issue - they cost businesses an average of $12.9 million annually.
- Environment uptime: Monitors the availability of testing environments and identifies incidents and risks caused by out-of-sync data.
It's not enough to monitor these metrics during normal conditions. Test them under stress to ensure the system performs consistently, even when under heavy load.
Stress Test for Scalability
Stress testing is essential to confirm that AI-powered synchronization can handle demanding scenarios. Simulate high traffic, sudden usage spikes, and unstable network conditions to identify potential bottlenecks before they impact production. While AI tools are designed to scale across multiple environments, devices, and browsers, stress tests validate that this scalability doesn’t come at the expense of speed or accuracy. By uncovering weak points during testing, teams can ensure the infrastructure is ready for real-world challenges.
Conclusion
Test data synchronization has long been a stumbling block for QA workflows, often leading to data gaps, manual errors, and unreliable tests. But AI is changing the game. With tools like anomaly detection, real-time validation, and predictive adjustments, AI can spot and fix discrepancies before they disrupt testing.
The impact of these AI-driven solutions is hard to ignore. For example, a leading financial firm slashed manual verification time by 60% using AI-powered validation, while a global retail company saw a 40% drop in data entry errors thanks to automated cleansing.
Building on these successes, Ranger combines AI-driven test creation with human oversight to ensure data accuracy across environments. Its integration with platforms like Slack and GitHub, alongside hosted infrastructure and real-time testing updates, makes it easier to maintain synchronization without complicating workflows.
These advancements highlight the importance of rethinking synchronization strategies. Adopting AI-powered test data management demands event-driven architectures, continuous performance monitoring, and rigorous stress testing to ensure scalability. For teams striving to keep test environments reliable, AI offers a practical way to streamline QA processes and meet the demands of modern development.
FAQs
How does AI keep test data in sync across dev, staging, and prod?
AI helps keep test data aligned across development, staging, and production environments by automating tasks like data generation, management, and masking. It can quickly generate synthetic, production-like data as needed while masking sensitive details to comply with privacy regulations. By maintaining consistent data, AI minimizes setup time, avoids discrepancies, and boosts testing reliability. This allows teams to replicate production scenarios and simplify workflows within CI/CD pipelines.
How can we use AI without copying real customer data?
AI has the ability to generate synthetic test data that mirrors actual patterns found in real-world scenarios. What's great is that it does this while keeping sensitive customer information completely secure. This approach helps maintain privacy and ensures compliance with regulations such as GDPR, CCPA, and HIPAA. By using synthetic data, teams can carry out thorough testing without the danger of exposing or mishandling real customer data.
What metrics should we track to prove sync accuracy is improving?
To gauge progress in sync accuracy, focus on metrics such as precision, recall, consistency, failure rates, and latency. These metrics provide insights into how well the synchronization process performs, ensuring data remains accurate and reliable.
Related Blog Posts
Stop babysitting your coding agents. Use Ranger
More signals, less noise, faster launches
Let Ranger be your guide to sustainable QA testing.

.png)