Managing Test Data for AI-Driven QA Testing



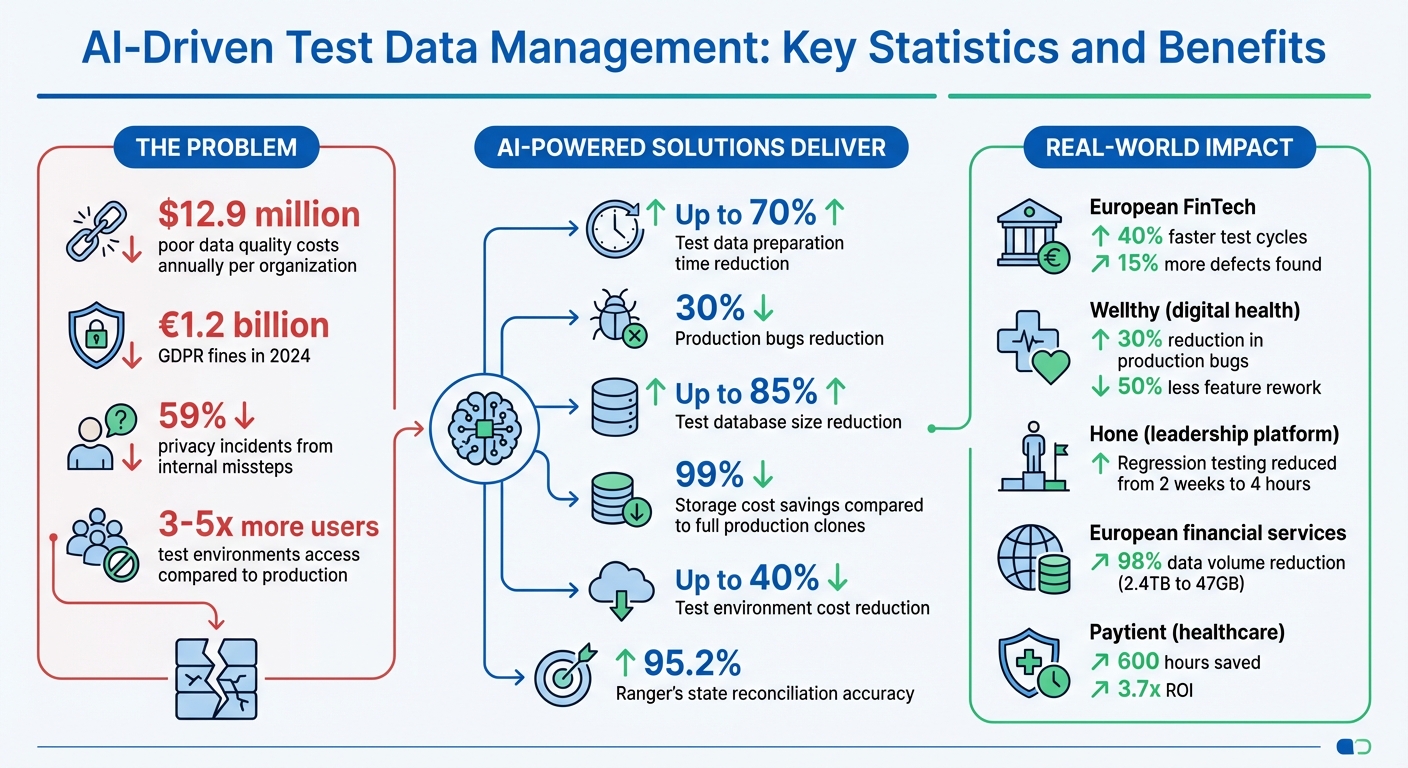
Test data management is a critical factor in the success of AI-powered QA testing. Without high-quality, diverse, and compliant data, testing workflows can suffer from inefficiencies, missed bugs, and compliance risks. Poor data quality costs organizations an average of $12.9 million annually, and in AI-driven environments, the stakes are even higher.
Key takeaways:
- AI-powered test data generation reduces preparation time by up to 70%, enabling faster development cycles.
- Synthetic data addresses privacy concerns and compliance with regulations like GDPR and CCPA, while also improving test coverage.
- Companies using AI for test data management report a 30% drop in production bugs and up to 85% reductions in test database sizes.
- Automating test data workflows and integrating them into CI/CD pipelines ensures efficiency and accuracy while minimizing bottlenecks.
AI-driven tools like Ranger simplify test data generation, automate compliance, and integrate seamlessly with existing workflows. By focusing on dynamic, secure, and up-to-date test data, organizations can improve testing accuracy, reduce costs, and maintain compliance.
AI-Driven Test Data Management: Key Statistics and Benefits
Eliminate Testing Bottlenecks AI Driven Test Data Automation Webinar
Common Test Data Management Challenges in AI-Powered Testing
AI-powered testing introduces a new level of complexity compared to traditional methods. The challenges stretch far beyond simply providing test data, touching on areas like infrastructure costs and regulatory hurdles. To address these demands, organizations need a well-thought-out approach to managing test data.
Managing Large Volumes of Complex Test Data
AI systems thrive on vast, diverse, and intricate datasets - something manual data creation simply cannot deliver. These systems require data that spans thousands of unique scenarios, such as edge cases, adversarial inputs, multilingual queries, and rare user behaviors. Unfortunately, many production databases lack this variety.
"AI systems fail because of bad data, not bad UI."
- Latha Narayanappa, AI Test Data Engineer
A common workaround is cloning entire production databases. However, this approach often leads to bloated datasets filled with irrelevant information, which inflates storage costs and slows down provisioning. On top of that, outdated training data can introduce biases and false positives, further diminishing test accuracy.
Data Privacy and Compliance Requirements
Using real production data for testing comes with serious risks. Regulations like GDPR, CCPA, HIPAA, and PCI-DSS impose strict rules on handling customer data. Violating these rules can be costly - GDPR fines alone totaled €1.2 billion in 2024, with test environments being flagged as frequent sources of data breaches. Alarmingly, 59% of privacy incidents stem from internal missteps, often during testing or development.
Staying compliant isn’t a one-and-done task. For example, GDPR’s Article 17 (Right to Erasure) mandates that companies respond to deletion requests across all environments, including backups and CI/CD artifacts, within a month. If handled manually, these requests can take up to 19 days, significantly increasing legal exposure.
Here’s how different data techniques stack up against GDPR/CCPA requirements:
| Technique | GDPR/CCPA Status | Data Utility | Re-identification Risk |
|---|---|---|---|
| Synthetic Data | No obligations | High (Statistical) | Near Zero |
| Anonymization | No obligations | Medium (Lossy) | Low (if K-anonymity applied) |
| Pseudonymization | Full obligations remain | High (Relational) | Medium (Reversible with keys) |
| Masked Production | Full obligations remain | Very High | High (Pattern matching) |
These challenges highlight the need for dynamic and secure test data approaches in modern testing landscapes.
Keeping Test Data Current and Relevant
Beyond managing large datasets and ensuring compliance, organizations must also focus on keeping test data up-to-date. While volume and compliance are immediate concerns, the issue of data drift adds a layer of ongoing complexity.
Test data can quickly lose relevance. Changes in schemas, business rules, or integrations can render yesterday’s data obsolete, leading to inaccurate test results. This phenomenon, known as "data drift", undermines the reliability of automated tests. As a result, tests may pass one day and fail the next - not due to coding errors, but because the data no longer mirrors production realities.
To counteract this, test data needs regular updates. Applications evolve constantly, and test data must keep pace with these changes to remain effective across development, QA, and staging environments. Manual updates, which can take days or even weeks, often create bottlenecks in CI/CD pipelines, leaving test data lagging behind the application.
A real-world example illustrates the impact of addressing this issue. In 2025, a European FinTech startup faced challenges due to GDPR restrictions that barred them from using real client data. Their manually created datasets couldn’t keep up with rapid feature rollouts. By implementing a fine-tuned generative AI model to produce synthetic datasets aligned with compliance standards, they cut test cycle times by 40% and uncovered 15% more functional defects in their fraud detection systems.
AI-Powered Test Data Generation and Synthetic Data Strategies
AI is transforming how test data is created. Instead of spending weeks manually assembling datasets, teams can now use AI to generate realistic and varied data in just minutes. This approach not only saves time but also addresses challenges like managing large volumes of data and meeting compliance requirements, offering a more efficient alternative.
Using AI to Generate Test Data
Models like GPT-4 and LLaMA 3 can create structured datasets that mimic real-world complexity without exposing sensitive information. These tools can generate everything from realistic names and addresses to intricate API payloads and transaction records. By analyzing patterns in existing data, AI can produce "virtual twins" that maintain statistical accuracy while ensuring no personally identifiable information is included.
Generative AI can reduce test data preparation time by up to 70%, freeing QA teams to focus on exploratory testing. Tasks that once required extensive manual effort - like ensuring referential integrity or covering rare edge cases - are now handled more efficiently by AI.
One standout feature is Agentic AI, which lets developers describe their data needs in plain English. For example, testers can request "a list of US airports" or "synthetic transaction data for fraud detection testing", and instantly receive tailored datasets. This natural language interface simplifies the process, making it faster and more accessible across development, QA, and staging environments.
Modern AI tools also analyze existing tests to define generation rules and seamlessly integrate scenario-specific data into CI/CD pipelines. With these capabilities, synthetic data offers benefits in areas like compliance, scalability, and defect detection.
Benefits of Synthetic Test Data
Synthetic data solves several challenges, from meeting privacy regulations to improving test coverage and reducing costs. Because synthetic datasets contain no actual personal information, they fall outside the scope of GDPR and CCPA regulations. This eliminates the legal risks of using production data clones and bypasses the need for complex anonymization processes that can take weeks to complete.
Organizations leveraging AI-driven test data management have reported up to 85% reductions in test database size and 99% savings on storage costs compared to using full production clones. Since AI can generate unlimited data from small samples, teams no longer need to maintain large, costly repositories that slow down provisioning.
AI also excels at producing rare edge cases that are often missing from production databases. Examples include unusual Unicode characters, leap-year scenarios, adversarial chatbot prompts, and multilingual queries. This diversity leads to better defect detection. For instance, Wellthy, a digital health company, used AI to create synthetic patient-provider communications for testing new features. By replicating linguistic patterns and medical terminology without using real protected health information, they achieved a 30% reduction in production bugs and halved feature rework.
However, human oversight remains crucial. While AI accelerates data generation, teams must validate the outputs to ensure they align with schema requirements and business rules. This prevents issues like "pattern lock-in", where generated data becomes repetitive or inaccurate. A hybrid approach - combining AI-generated synthetic data with anonymized production samples - often provides the best balance of realism and coverage.
Integrating Test Data Management into Continuous Testing Pipelines
Continuous testing pipelines require fresh, compliant test data at every stage - whether it's for development, staging, or production. Traditional methods often slow things down, but modern Test Data Management (TDM) automates these workflows, making continuous testing much smoother. This approach ensures that high-quality, compliant datasets are always on hand, boosting efficiency, accuracy, and regulatory compliance - key pillars of effective testing.
Automating Test Data Workflows
Automation takes the hassle out of managing test data, turning it into a seamless part of the pipeline. Tasks like data cloning, masking, and subsetting now happen automatically, ensuring that high-quality datasets are always ready for use across different environments. Self-service tools also empower QA engineers to refresh datasets on their own, speeding up release cycles and avoiding pipeline delays.
Next-gen systems go a step further by generating domain-specific test data on demand. For example, a simple natural language prompt like "a list of US airports" can instantly provide relevant data. This approach allows organizations to prepare test data up to 70% faster compared to manual methods.
Organizing test data into categories - such as positive, negative, stress, or regression - lets automated scripts pull the right datasets for each stage of the testing pipeline. Data versioning ensures that datasets stay aligned with current code and business rules, reducing the risk of false positives. A great example is Chainyard, the company behind the "Trust Your Supplier" platform. In 2025/2026, they adopted AI-driven test data generation to stay compliant with GDPR and HIPAA. Their system automatically created synthetic supplier profiles that mimicked real-world patterns, cutting out manual data prep and keeping test data in sync with production schemas.
These automated workflows integrate seamlessly with CI/CD processes, making the entire pipeline even more efficient.
Integrating with CI/CD Tools
Beyond automation, integrating TDM directly with CI/CD tools takes continuous testing to the next level. Tools like Jenkins, Azure DevOps, and Jira can work hand-in-hand with automated data workflows to ensure every test run starts with compliant datasets provisioned during the build process.
Data virtualization solutions also play a big role here, delivering virtual copies of data that require minimal storage and can be provisioned in minutes. This reduces storage needs by over 90%. Meanwhile, AI-powered profiling keeps data generation rules synchronized with CI/CD pipelines, eliminating the need for manual updates.
BT Group, a global communications leader, is a prime example of the benefits. By adopting AI-driven test data solutions, they saved millions of dollars while streamlining data creation and improving testing efficiency. Embedding TDM into CI/CD pipelines not only eliminates the compliance risks of using production clones but also ensures the statistical accuracy needed for realistic testing scenarios.
sbb-itb-7ae2cb2
Best Practices for Test Data Maintenance and Governance
Even with advanced AI-driven testing, keeping your test data well-maintained and properly governed is essential. Regular updates ensure that test data remains effective. Companies that manage test data as a dynamic resource report 30% fewer production bugs and can cut test environment costs by up to 40%.
Regular Test Data Refresh Cycles
Test data needs to align with your production environment to avoid testing against outdated or irrelevant scenarios. When schemas evolve, features update, or dependencies shift, "data drift" can occur. This drift often results in flaky tests or false positives, wasting valuable engineering time.
To combat this, incorporate automated refresh cycles into your CI/CD pipeline. This ensures test data is consistently updated between runs, maintaining accuracy and eliminating interference from previous test states. Modern self-service tools now allow QA teams to quickly pull fresh, masked data in minutes, eliminating the delays associated with manual requests.
For example, in 2024, Hone, a leadership training platform, adopted automated test data provisioning under the guidance of Senior Software Engineer Jason Lock. This change reduced their regression testing time from two weeks to just four hours.
"Before we had... production-quality data for our engineers and QA, we would see critical issues at least once a week... Now, we haven't had a critical issue since we fully operationalized Tonic into our software development life cycle. That was nine months ago." – Jason Lock, Senior Software Engineer and Tech Lead, Hone
Another best practice is treating test data like versioned code. By linking datasets to specific releases or test cycles, you can preserve reproducibility and simplify root-cause analysis when issues arise. While updated test data is critical, strong governance policies are equally important to ensure compliance and security.
Implementing Data Governance Policies
In addition to regular refresh cycles, effective governance policies ensure your testing process remains both compliant and efficient. The stakes are high: in 2024, GDPR fines totaled €1.2 billion, with 335 breach notifications reported daily across the EU. Test environments often have 3–5 times more users with access than production environments, increasing the risk of exposure.
Start by classifying your data and controlling access. AI-powered tools can identify sensitive information, such as PII, across all environments - even in overlooked developer databases. Implement Role-Based Access Control (RBAC) and adhere to the principle of least privilege, ensuring only authorized personnel can access or create test datasets.
A European financial services company offers a great example. In 2024, they reduced their test data volume from 2.4TB (600 million records) to just 47GB (8 million records) - a 98% reduction - by filtering unnecessary tables, columns, and rows. This not only reduced GDPR breach risks but also made managing data subject rights much simpler.
Minimizing data is key. By extracting only the data necessary for testing, you can reduce regulatory risks and storage costs. Clear storage policies, such as automated expiration after 90 days, also help meet GDPR Article 5 requirements.
For instance, Paytient, a healthcare credit provider, automated its test data masking processes under VP of Engineering Jordan Stone. This saved 600 hours of development time and delivered an ROI of 3.7x.
Lastly, maintain detailed audit trails to track data lineage, access logs, and masking verification. Automated workflows can also simplify compliance with "Right to Erasure" requests. One European e-commerce platform, for example, reduced the time needed to process Article 17 erasure requests from 19 days of manual coordination to just six hours using centralized automation.
Using Ranger for AI-Driven Test Data Management
Ranger offers a smart solution for managing the challenges that come with large-scale, complex, and compliance-driven test data. By using AI, Ranger’s QA testing platform streamlines test data management, tackling common obstacles with automation and advanced oversight. It integrates directly into existing workflows, cutting down on manual effort, speeding up testing cycles, and ensuring the accuracy and compliance standards that enterprise teams require.
Key Features of Ranger for Test Data Management
Ranger simplifies test data creation by using AI to generate over 50 types of synthetic test data. This includes items like credit card numbers, SSNs, Google Authenticator codes, emails, and phone numbers. By doing this, it eliminates the need to extract and mask production data, reducing privacy risks and significantly saving preparation time.
Manual testers can also benefit from Ranger’s ability to transform plain English commands into complex test cases without requiring coding knowledge. This feature expands test coverage by making it easier to create detailed tests based on everyday language.
The platform integrates seamlessly with tools like Slack and GitHub, embedding test data workflows into continuous testing processes. For example:
- Slack webhooks enable real-time alerts about test data anomalies and pipeline updates.
- GitHub Actions support automated testing and documentation from the very start, ensuring smooth CI/CD integration.
Ranger also employs an autonomous OPAV loop (Observe → Plan → Act → Verify), allowing AI agents to continuously refine testing cycles. This loop automates the generation, execution, and verification of test data without manual involvement. Additional features like Prisma for data orchestration and contextual memory management maintain consistency, while encrypted vaults ensure a zero-trust security model.
These capabilities come together to boost both efficiency and accuracy, as outlined below.
How Ranger Improves Efficiency and Accuracy
Ranger’s verification-driven approach achieves an impressive 95.2% accuracy in state reconciliation models, minimizing false positives and better reflecting real-world application behavior. This level of precision is the result of over 4,000 hours of research into production-grade autonomy. As a result, it reduces the need for manual rework and eliminates common bottlenecks.
Additionally, Ranger’s self-healing technology automatically updates test scripts to adapt to changes in user interfaces, dynamic object IDs, and system updates. This drastically cuts down on the maintenance burden that often accompanies traditional automation tools.
Conclusion
Managing test data effectively has become a cornerstone for success in AI-driven QA testing. As Patrícia Duarte Mateus from TestRail explains:
"Test data management takes testing out of the realm of guesswork and turns it into a disciplined, measurable process that fuels reliable releases."
Organizations adopting AI-powered test data management have reported impressive results: 70% faster data preparation, 30% fewer production bugs, and a reduction in total test environment costs by up to 40%.
Switching from manual test data management to AI-driven methods tackles major pain points. Automated provisioning slashes data preparation time from days to minutes, while intelligent masking ensures compliance with regulations like GDPR, HIPAA, and CCPA without disrupting workflows. These advancements, when integrated into CI/CD pipelines, eliminate flaky tests and provide the stable, reliable datasets that continuous testing requires.
To sustain these benefits, it’s crucial to treat test data as a priority asset. This means implementing clear governance, version control, and regular refresh cycles. Whether you're creating synthetic datasets at runtime, using entity-based micro-databases for microservices, or automating data subsetting to manage storage costs, the objective is clear: deliver realistic, secure, and readily accessible data that accelerates testing without compromising compliance.
Platforms like Ranger showcase how this can be done seamlessly. By automating synthetic data generation, integrating with tools like Slack and GitHub, and blending AI-driven automation with human oversight, Ranger simplifies the entire process. This approach transforms test data management into a strategic advantage, enabling faster feature releases and better bug detection before production.
Focus on automating data provisioning, refreshing datasets regularly, and leveraging synthetic data to broaden test coverage. The effort invested in refining test data management results in quicker releases, fewer production issues, and development teams that can dedicate more time to building exceptional software.
FAQs
How can I tell if synthetic test data is realistic enough?
To figure out if synthetic test data feels realistic, you’ll want to compare its statistical properties - things like distributions, correlations, and patterns - with actual production data. It’s important that the synthetic data mirrors real-world scenarios while sticking to the business rules that make sense for your use case.
There are tools available that can help assess data quality without needing annotations. These tools focus on ensuring the data strikes a balance between realism and privacy compliance. Ultimately, synthetic data should closely replicate the statistical and logical traits of production data to make testing both reliable and effective.
What’s the safest way to use production data without breaking compliance?
When working with production data, the safest approach involves applying data sanitization and anonymization techniques. This can include methods like data masking, removing or altering sensitive details such as PII (Personally Identifiable Information), or even generating synthetic data. These steps help protect privacy while still retaining the data's usefulness for testing or analysis.
Using AI-generated synthetic data is another effective option, as it ensures privacy and aligns with regulations like GDPR, HIPAA, and CCPA. Automating these processes can simplify the task of maintaining compliance, especially in test environments where data security is critical.
How can I keep test data in sync with CI/CD as schemas change?
AI-powered tools like Ranger take the hassle out of managing test data by automating tasks like synthetic data generation, masking, subsetting, and on-demand provisioning. They ensure your test data stays in sync with changing schemas by generating production-like, privacy-safe data. This not only ensures consistency but also cuts down on the manual work involved in continuous integration and deployment processes.
Related Blog Posts
Stop babysitting your coding agents. Use Ranger
More signals, less noise, faster launches
Let Ranger be your guide to sustainable QA testing.

.png)