AI for Production-Like Test Data Creation


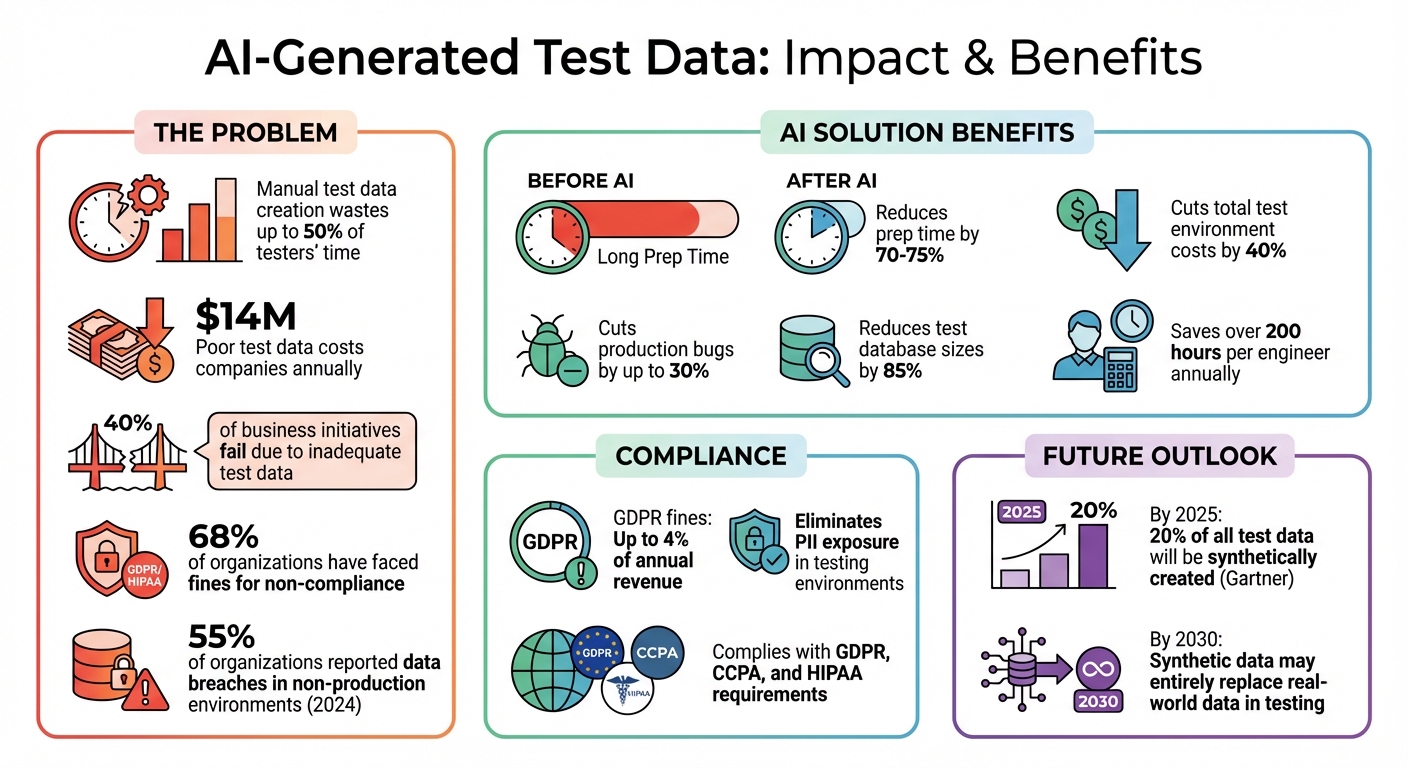
Testing software is faster, safer, and more accurate with AI-generated data. Here's why: manual test data creation wastes up to 50% of testers' time, and using production data risks privacy violations. AI now generates synthetic test data that looks and behaves like real data - without exposing sensitive information. This ensures compliance with GDPR, CCPA, and HIPAA while maintaining statistical accuracy and business logic.
Key Highlights:
- Why It Matters: Poor test data costs companies $14M annually and causes 40% of business initiatives to fail.
- AI Benefits:
- Creates realistic, privacy-safe test data.
- Reduces preparation time by 70–75%.
- Cuts production bugs by up to 30%.
- Techniques Used: AI models like GANs and VAEs analyze production patterns to generate synthetic data.
- Compliance: Eliminates PII exposure in testing environments, avoiding fines of up to 4% of annual revenue under GDPR.
- Use Cases: Fraud detection, load testing, and rare edge case simulation.
AI-driven test data creation is transforming quality assurance, saving time, reducing costs, and improving software reliability. By combining automated QA engineering with human oversight, teams can prepare safer, production-like datasets for testing without sacrificing security or accuracy.
AI Test Data Generation: Key Statistics and Benefits
Solving data bottlenecks with Agentic AI: Automate your synthetic test data
Planning Your Test Data Requirements
Carefully planning your data needs, expected volume, and rules is a must before generating test data. Without clear planning, synthetic data might look realistic but fail to catch bugs or even violate compliance rules.
Defining Your Testing Needs
Start by identifying the key data domains you’ll need, like user profiles, transactions, payment records, and product catalogs. For each domain, establish relationships between tables. For instance, a user’s age should match their date of birth, and account types should align with activity levels. These relationships are essential for maintaining referential integrity in your database.
Next, figure out the scale of your testing. Whether you’re targeting a single feature or simulating 100,000 concurrent users for load testing, automating test data creation can save immense time. In fact, testers often spend up to 50% of their time waiting for or manually creating test data. Make sure your test data is up-to-date, reflecting your current production schema and business logic, especially as your system evolves.
Don’t overlook edge cases. Random dummy data rarely includes scenarios like a customer with an expired credit card but an active subscription, or a user who signs up, upgrades, cancels, and reactivates. These rare but realistic situations can reveal critical bugs.
Once you’ve defined your testing needs, it’s time to address compliance and privacy requirements.
Meeting Compliance and Privacy Requirements
With your testing needs outlined, ensure your test data meets strict compliance and privacy standards.
Privacy regulations like GDPR, CCPA, and HIPAA set clear rules: raw production data cannot be used in test environments. The penalties are steep - under GDPR, fines can reach up to 4% of a company’s annual revenue. Alarmingly, 68% of organizations have faced fines for non-compliance with regulations like GDPR or HIPAA.
Start with data discovery. Use automated tools to identify sensitive information such as Personally Identifiable Information (PII) - names, Social Security numbers, email addresses, and bank details - or Protected Health Information (PHI) for healthcare settings. In 2024, 55% of organizations reported data breaches involving sensitive information in non-production environments. These breaches often occur when PII isn’t properly mapped or protected during testing.
The right compliance strategy depends on your use case. Anonymization (irreversible) is ideal for external sharing or analytics, while pseudonymization (reversible) works well for internal testing where tracing issues back to production patterns is necessary. For example, Paytient, a health payment platform, implemented automated de-identification to safeguard sensitive payment and health data. This strategy saved hundreds of engineering hours and reduced PII leak risks, delivering a 3.7× ROI.
To further secure your test data, implement Role-Based Access Controls (RBAC) to limit who can view or modify it. Maintain centralized logging for audit purposes, rotate encryption keys every 90 days, and securely dispose of test data once it’s no longer needed.
With compliance and testing needs covered, the next step is choosing the right AI strategy for data synthesis.
Selecting an AI Data Strategy
AI provides three main methods for generating test data: rule-based generation, model-based synthesis, and hybrid approaches. Each has distinct advantages depending on your data’s complexity and your testing goals.
Rule-based generation relies on predefined logic to enforce business rules, handle edge cases, and maintain relationships between tables. For example, you can define rules ensuring all user records include valid email formats or that transaction timestamps occur during business hours. While effective, this method requires extensive manual setup and may lack the statistical depth of real-world data.
Model-based synthesis uses AI techniques like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) to analyze patterns in production data and generate entirely new datasets. This approach captures intricate distributions and correlations, making it ideal for machine learning training or analytical testing. However, it’s computationally demanding and may struggle with consistency across related tables.
Hybrid strategies combine the strengths of both approaches. Rules ensure business logic is followed, while AI models add statistical realism. For instance, Flexport streamlined test data generation for over 30 engineering teams by integrating synthetic data creation into its schema migration process. This ensured developers had access to compliant, up-to-date databases for every feature branch - without exposing production data.
When deciding on a strategy, consider your priorities. If compliance is critical, focus on rule-based or hybrid methods with built-in anonymization. If you’re training machine learning models, model-based synthesis can provide the realism needed. Just remember to ground your AI generation in high-quality real-world "seed" data to avoid issues like model collapse, where AI performance degrades from training on its own output.
"The examples through which you seed the generation need to mimic your real-world use case." - Akash Srivastava, Chief Architect, InstructLab
Generating Synthetic Data with AI
Creating high-quality synthetic data with AI involves a structured approach. You'll need to prepare your source data, set up AI models to understand your schema, and validate the output to ensure it's suitable for use in testing. Here's how to tackle each step effectively.
Preparing Your Source Data
To generate realistic test data, AI needs a clear understanding of your database schema and data patterns. Start by extracting your database schema, which includes the tables, columns, data types, and constraints. Instead of using real data, replicate this structure with metadata clones. This protects sensitive information like Personally Identifiable Information (PII) while still providing the framework AI models require.
Next, profile your data to capture key statistics like means, variances, and distributions. This step ensures the AI understands how your real data behaves. For instance, if customer ages typically range from 18 to 75 with a median of 42, the AI will generate synthetic ages that follow a similar pattern.
Clean your seed data by addressing duplicates, inconsistencies, and missing values. Poor-quality input will lead to poor-quality synthetic output.
"The examples through which you seed the generation need to mimic your real-world use case." – Akash Srivastava, Chief Architect, InstructLab
For relational databases, identify join keys - columns like customer IDs or order numbers that link tables. This ensures the AI generates consistent values across tables, maintaining referential integrity. If you're working under the HIPAA Safe Harbor method, remember to remove 18 specific identifiers, such as names, Social Security numbers, and detailed date elements (except the year). For Snowflake users, classify string columns as "categorical" if the number of unique values is less than half the row count, and ensure each table has at least 20 distinct rows.
Setting Up AI Models
Once your source data is ready, configure your AI models to produce synthetic records that align with your schema and business rules. A combination of rule-based constraints and model-based synthesis works best. Rules ensure strict adherence to formats like U.S. ZIP codes (5 digits or ZIP+4), Social Security numbers (XXX-XX-XXXX), and standardized currency formats ($1,234.56). Meanwhile, AI models capture the statistical distributions and correlations in your data.
Generative Adversarial Networks (GANs) are a popular choice for this purpose. They use two neural networks: one generates synthetic data, and the other evaluates its authenticity. Over time, the generator improves its output to produce more realistic data. Another option is Variational Autoencoders (VAEs), which compress real data into a simplified representation and decode it to create new synthetic records. VAEs are particularly effective for complex, continuous data distributions.
Use schema-driven prompts and 5–10 real examples to guide the AI in generating data that matches your field formats and business logic. For example, when creating synthetic employee records, provide examples with realistic job titles, salary ranges, and hire dates that reflect your organization's patterns.
To protect privacy, apply filters that block synthetic data resembling real records too closely. Metrics like Nearest Neighbor Distance Ratio (NNDR) and Distance to Closest Record (DCR) help identify and exclude such rows. For consistency across multiple runs, use a symmetric string secret when generating join keys, ensuring they remain identical across sessions.
Start with small batches of data and validate the results before scaling up.
Creating and Validating Test Data
Begin by generating smaller batches of synthetic data to verify quality before scaling. For larger datasets, break the task into smaller chunks and process them in parallel. Use status tables to monitor row counts, checksums, and error codes for each segment.
Validation involves several steps. First, check the fidelity of the data by comparing statistics like means, medians, variances, and distributions. Tools like histograms and correlation coefficients can help with this. Next, assess the utility of the data. For example, if you're training machine learning models, compare their performance - accuracy, precision, and recall - when trained on synthetic data versus real data. Finally, confirm relational integrity by ensuring foreign keys match across tables, date sequences make sense (e.g., order dates precede shipping dates), and calculated fields are accurate. Automated checks should flag any anomalies, biases, or missing values.
While automated metrics are essential, don't rely on them entirely.
"Rely on metrics, rely on benchmarks, rigorously test your pipeline, but always take a few random samples and manually check that they are giving you the kind of data you want." – Akash Srivastava
Manually review 5 to 10 random records to ensure they meet your standards and don't inadvertently expose sensitive information. This final step ensures your synthetic data is both reliable and safe to use.
sbb-itb-7ae2cb2
Masking and Subsetting Production Data with AI
In addition to synthetic data generation, teams can improve test environments by using data masking and subsetting. These techniques convert production data into safer test environments while maintaining its essential characteristics.
Building a Data Masking Strategy
Data masking involves transforming production data by replacing sensitive information with fictitious yet structurally similar content. This ensures privacy is protected without compromising the data's utility for testing purposes.
The first step is to identify fields containing sensitive information. AI-powered Named Entity Recognition (NER) models can automatically detect and flag Personally Identifiable Information (PII) in both structured and unstructured datasets.
Once identified, apply masking rules tailored to the type of data. For example:
- Shift timestamps consistently across the dataset.
- Remap ZIP codes while preserving demographics.
- Replace names with culturally consistent alternatives.
Even with masking in place, it's critical to limit access to production-derived data and implement audit trails to track its usage.
Creating Data Subsets with AI
Production databases are often too large for local development or testing, making subsetting a practical solution. Data subsetting extracts a smaller, manageable sample of production data while maintaining its integrity. AI tools can analyze database schemas, constraints, and relationships to ensure that the subset retains referential integrity across related tables.
Define subsetting criteria based on your testing requirements. This might include isolating data by region, focusing on transactions within a specific time frame, or extracting a representative random sample. Some AI tools even allow you to define these criteria using natural language prompts.
During subsetting, it's essential to apply masking rules and differential privacy techniques to prevent any sensitive data from being exposed in test environments. For instance:
- Flywire, operating under HIPAA regulations, initially spent 40 hours manually creating synthetic datasets. By automating subsetting and masking, they reduced environment setup time to just minutes, enabling on-demand test environments.
- Paytient saw a 3.7× return on investment and saved hundreds of engineering hours by shifting from manual data creation to automated processes.
Synthetic Data vs. Data Masking
Both data masking and synthetic data serve different purposes in testing. Data masking retains the unique features and anomalies of real datasets, making it ideal for integration testing and resolving production issues. On the other hand, synthetic data eliminates privacy risks entirely by generating records based on statistical patterns, making it a better fit for greenfield development or testing rare edge cases.
| Feature | Data Masking | Synthetic Data | Data Subsetting |
|---|---|---|---|
| Privacy Risk | Moderate (risk of re-identification) | Low (no ties to real individuals) | Varies (depends on masking applied) |
| Realism | High (uses real structures and anomalies) | Very High (statistical patterns) | High (actual production data) |
| Effort | Moderate (requires PII detection) | High (requires AI training) | Low (automated extraction) |
| Best Use Case | QA testing, targeted debugging | AI/ML training, high-compliance scenarios | Local development, performance testing |
Many teams opt for a hybrid approach, combining masking for real-world scenarios, synthetic generation for new features, and subsetting to manage database size. By integrating these methods, teams can build a comprehensive, privacy-conscious strategy for creating production-like test environments. This approach complements earlier techniques, offering a versatile toolkit for test data preparation.
Using AI-Generated Test Data with Ranger
Once you've generated synthetic or masked data, the next step is integrating it into your QA processes with Ranger. This ensures your test data performs reliably in environments that mimic production. Ranger's platform combines automated test creation with human oversight, helping you catch bugs before they reach production.
Adding Test Data to Your QA Automation
Ranger works seamlessly with GitHub to automatically run Playwright test scripts whenever code changes are made. It also integrates with Slack to instantly notify your team about test results, so you're always in the loop when issues arise. Whether you're migrating an existing Playwright suite or starting fresh, Ranger's automation handles browser setups and test execution, ensuring bugs are caught early. This blend of machine efficiency and human insight takes quality assurance to the next level.
"Ranger helps our team move faster with the confidence that we aren't breaking things. They help us create and maintain tests that give us a clear signal when there is an issue that needs our attention." – Matt Hooper, Engineering Manager, Yurts
Using Human Oversight in AI Workflows
Ranger's AI agent generates test scripts and performs initial bug triaging, but the process doesn’t stop there. A team of QA Rangers reviews each test to ensure clarity and reliability. This human-in-the-loop approach ensures that AI-generated test data meets high standards and aligns with your application's behavior, even as your product evolves. Some customers have reported saving over 200 hours per engineer annually by offloading repetitive testing tasks.
By combining human expertise with AI capabilities, Ranger creates a system where structured feedback continuously improves the quality of test data.
Building Feedback Loops for Improvement
Every test failure or production incident offers an opportunity to refine AI data generation. Ranger’s monitoring system feeds test results and application updates back into its AI model, enhancing accuracy over time. When tests fail, automated triaging helps distinguish between genuine bugs and data inconsistencies. Human reviewers then confirm issues and flag any data quality problems. This feedback loop helps teams identify real regressions versus flaky tests, enabling problematic datasets to be quarantined and improved.
Conclusion
AI-powered test data creation is reshaping quality assurance, slashing preparation time by an impressive 70–75% and reducing production bugs by up to 30%. This approach generates synthetic datasets that fully comply with regulations like GDPR, CCPA, and HIPAA, all while preserving the intricate relational structures and business rules necessary for effective testing.
By blending rule-based generation with model-driven synthesis, organizations achieve both precise business logic and realistic statistical patterns. This hybrid method has led to an 85% reduction in test database sizes and cut total test environment costs by as much as 40%.
"In my projects, generative AI cut test data prep time by 70%, freeing up QA resources for exploratory testing." – Laura Bennett, Lead QA Architect at SoftEdge Labs
While automation drives much of the progress, human involvement remains critical. Manual validation of random samples complements automated metrics, ensuring that synthetic data aligns with real-world scenarios. Tools like Ranger streamline this process by incorporating AI-generated test data directly into CI/CD pipelines, combining automated testing with human review to maintain high-quality standards.
The future of testing is shifting toward synthetic-first, on-demand data generation. Gartner estimates that by 2025, 20% of all test data will be synthetically created. By 2030, synthetic data may entirely replace real-world data in testing workflows. Integrating AI-driven data generation into automated processes not only speeds up feature releases but also ensures testing quality that mirrors real-world conditions.
FAQs
How does AI-generated test data protect user privacy and comply with regulations?
AI-generated test data offers a smart way to maintain privacy and meet regulatory standards. By creating synthetic data that mirrors real-world production data, it eliminates the need to expose actual user information. Techniques such as differential privacy add controlled noise to the data, making it impossible to trace back to individual records. On top of that, de-identification methods strip or generalize sensitive details, ensuring that personally identifiable information (PII) is protected before being analyzed by AI.
Ranger integrates these cutting-edge privacy techniques into its AI-driven QA platform. It generates realistic, production-like test data while complying with privacy regulations like GDPR, CCPA, and HIPAA. This enables software teams to conduct thorough testing without the risk of exposing sensitive data.
What’s the difference between synthetic data and data masking in test data creation?
When it comes to protecting privacy while creating test data, synthetic data and data masking take two very different paths.
Synthetic data is entirely generated by algorithms or AI to replicate the patterns and relationships found in real-world data. The key here is that it doesn’t use any actual production records. Because it’s completely artificial and free of real personally identifiable information (PII), it’s inherently safe to share and use, whether for testing or training models.
Data masking, however, works directly with real production data. It modifies or obscures sensitive details - like names or Social Security numbers - while maintaining the structure and relationships within the dataset. This approach ensures teams can work with realistic data without risking exposure of private information.
To sum it up: synthetic data is fully generated and contains no real PII, while data masking transforms actual data to safeguard sensitive details while keeping it functional for testing.
How does AI-powered test data creation save time and reduce costs in software testing?
AI-driven test data creation takes the hassle out of generating realistic, production-like data. It slashes manual data preparation time by an impressive 60–90%, allowing teams to dedicate more energy to testing and development. The result? Faster project timelines and more efficient workflows.
Beyond saving time, this method also cuts costs by reducing labor-intensive tasks and providing high-quality, reusable test data. With AI managing data creation, software teams can identify bugs sooner, streamline processes, and roll out features at a much quicker pace.
Related Blog Posts
Stop babysitting your coding agents. Use Ranger
More signals, less noise, faster launches
Let Ranger be your guide to sustainable QA testing.

.png)