Training AI Models with QA Expertise: Guide



AI model reliability starts with quality assurance (QA). QA professionals ensure data accuracy, test edge cases, and monitor performance with a metrics analyzer to build trustworthy systems. Unlike traditional software testing, AI testing evaluates variable outputs for relevance and consistency.
Key takeaways:
- Data Quality Matters: High-quality training data improves AI performance by 30–50%.
- QA's Role: QA is involved at every stage - data preparation, training, validation, deployment, and monitoring.
- Bias Detection: QA teams identify and reduce biases using risk analysis, ensuring fair and balanced outputs.
- Edge Case Testing: Targeted datasets and adversarial testing strengthen model reliability.
- Continuous Monitoring: QA tracks model performance, detects drift, and triggers retraining when needed.
QA expertise is critical to creating AI systems that perform effectively under real-world conditions. This guide covers actionable strategies for QA teams to improve AI testing and collaboration with data scientists.
QA in ML
sbb-itb-7ae2cb2
QA's Role in the AI Model Lifecycle
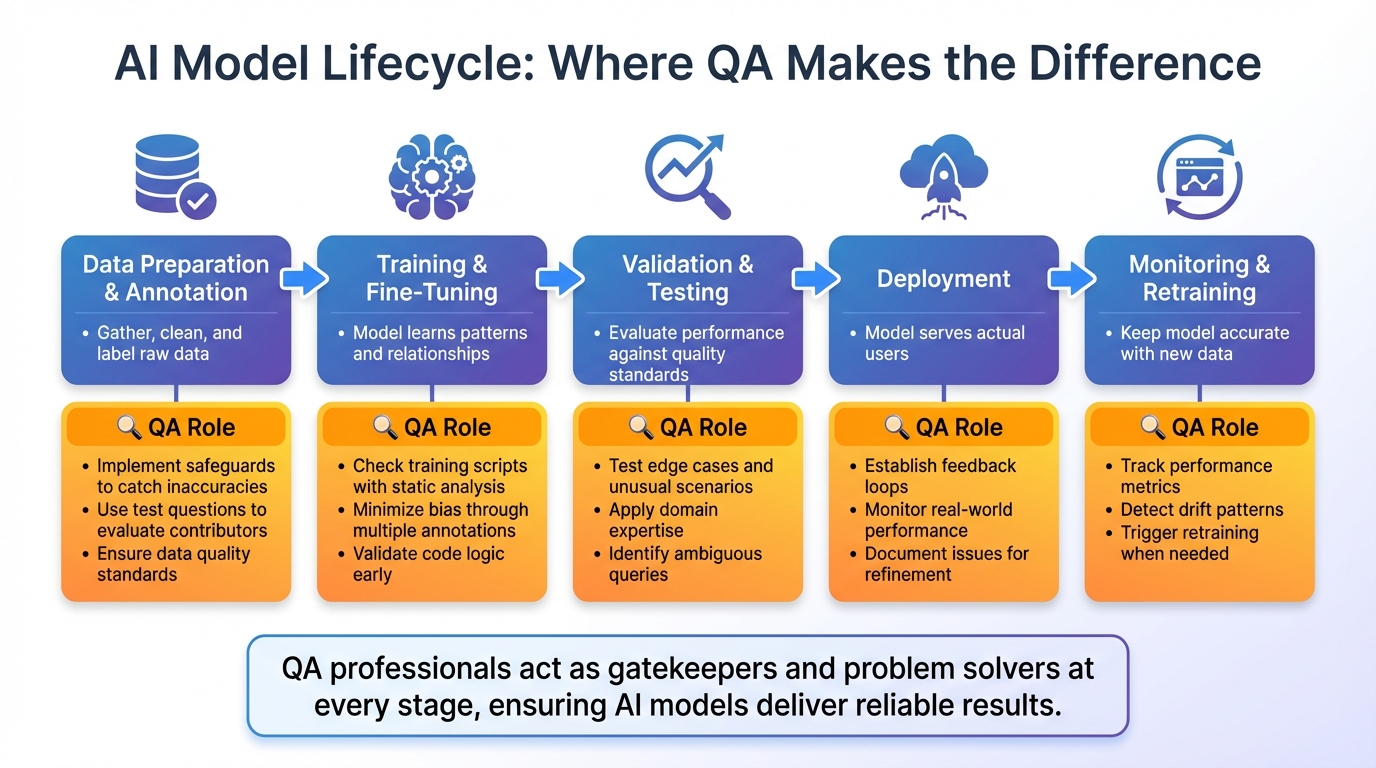
AI Model Lifecycle with QA Integration: 5 Critical Stages
The AI Model Lifecycle Stages
Developing an AI model is a step-by-step process that moves from an initial concept to a fully operational system. It kicks off with data preparation and annotation, where raw data is gathered, cleaned up, and labeled. Then comes training and fine-tuning, where the model learns patterns and relationships from the prepared data. The next stage is validation and testing, where the model's performance is rigorously evaluated against quality standards. Once it meets these benchmarks, the model advances to deployment, where it starts serving actual users. Finally, monitoring and retraining keep the model accurate and relevant as new data becomes available.
Each of these stages comes with its own set of challenges, from ensuring the data is clean to avoiding overfitting during training. This is where QA (Quality Assurance) plays a critical role. QA professionals are involved at every step, ensuring the process runs smoothly and the model delivers reliable results.
What QA Professionals Contribute
QA teams are essential in maintaining quality across the AI model lifecycle by addressing challenges unique to each stage. Their role is twofold: they act as both gatekeepers and problem solvers, ensuring high standards throughout.
During data preparation, QA teams focus on preventing errors right at the source. They implement safeguards to catch inaccuracies and duplicates before they can impact the model. QA also uses "test questions" - pre-labeled data with known answers - to evaluate the accuracy of contributors. This ensures only qualified individuals handle the training data.
In the training phase, QA professionals check the training scripts using static analysis techniques like code linting and type checking to catch logic errors early. They also minimize bias by requiring multiple annotations for each data point. During validation, QA goes beyond standard performance metrics by testing edge cases - those tricky scenarios automated systems often overlook. This is where domain expertise shines, as QA identifies unusual inputs, ambiguous queries, or rare situations that could cause the model to falter.
Once the model is deployed, QA's job is far from over. They establish feedback loops to monitor real-world performance. By documenting issues like misclassifications and unexpected behaviors, QA provides data scientists with critical insights for model refinement and retraining. This continuous oversight is vital, especially when you consider that 65% of AI projects fail due to issues like poor coordination, data problems, and unclear objectives. Effective QA practices bridge the gap between a model's theoretical capabilities and its real-world performance, ensuring it consistently meets user expectations.
Tools like Ranger (https://ranger.net) assist QA teams by offering AI-powered testing services combined with human oversight, making the process more efficient and reliable.
Preparing Quality Training Data with QA Expertise
The quality of training data directly affects the performance of AI models. As the saying goes, "Garbage in, garbage out". QA professionals play a key role in ensuring that the data used for training is accurate, complete, and well-suited for the model's purpose. By catching data issues early through systematic processes, QA teams turn raw data into a solid foundation for training.
Verifying Data Accuracy and Completeness
To ensure data accuracy and completeness, QA teams can follow a three-step cleaning process:
- Deduplication: Remove near-duplicate entries.
- Quality filtering: Eliminate errors and inconsistencies.
- Gap analysis: Identify missing knowledge areas.
For a dataset to be minimally viable, it should include at least 1,000 high-quality QA pairs. For optimal results, aim for 50,000 or more pairs. When multiple annotators are involved, tracking agreement metrics like Cohen's Kappa (for categorical labels) or Krippendorff's Alpha (for imbalanced or ordinal classes) is critical. These metrics ensure consistent interpretation of guidelines. Maintaining "gold sets" - high-quality, pre-labeled datasets - helps QA teams calibrate annotators, audit performance, and reset standards when needed.
Exploratory Data Analysis (EDA) is another crucial step. It helps uncover patterns, relationships, and quality issues early in the process. During this stage, QA teams should watch for errors such as incorrect unit conversions or overly precise measurements that don't align with the sensitivity of the instruments used. Additionally, human tendencies like rounding to the nearest 0 or 5 can introduce artificial patterns that don't reflect reality.
For precise verification, structuring data as Question-Answer-Fact triplets can be effective. This method includes a specific question, an ideal answer, and a concise "fact" (usually three words or fewer). This structure allows for deterministic evaluation using metrics like "Factual Knowledge" and "QA Accuracy" to compare model performance against ground truth. A risk-based approach for Human-in-the-Loop (HITL) review can further enhance quality by assigning risk levels (Low, Medium, High, Critical) to determine the percentage of data requiring manual validation by subject matter experts.
Once data accuracy is established, the next challenge is addressing biases that could compromise the model's fairness.
Finding and Reducing Bias in Data
After verifying accuracy, QA teams must ensure the dataset is free of bias. Stress-testing datasets for systematic biases, such as underrepresentation of certain dialects or demographics, is a critical step.
"Fairness in AI starts with data quality. Without systematic dataset audits, you're flying blind."
- Margaret Mitchell, Chief Ethics Scientist, Hugging Face
Demographic parity scans are a good starting point. By comparing label distributions across subgroups (gender, age, region), QA teams can identify imbalances that may lead to biased outcomes. Another effective method is counterfactual swap testing, where attributes like names or pronouns are swapped. If changing "John" to "Maria" or "he" to "she" causes significant shifts in model output, bias is likely present and needs to be addressed.
| Feature | Internal Manual Labeling | External (Crowdsourced) | Programmatic Labeling |
|---|---|---|---|
| Expertise | High (Subject Matter Experts) | Low to Moderate | High (via heuristics/rules) |
| Scalability | Low | High | Very High |
| Cost | High | Linear (Fixed per label) | Budget-friendly |
| Privacy | High | Low (Privacy concerns) | High |
| Best Use | Core business/Medical data | General knowledge | Large-scale, fast-moving data |
QA teams should also be mindful of the surrogate endpoint problem, where proxy labels don't accurately represent the real goal. Similarly, survivorship bias - using only "surviving" data points - can skew results. As Ben Jones, author of Avoiding Data Pitfalls, explains:
"It's not crime, it's reported crime. It's not the number of meteor strikes, it's the number of recorded meteor strikes."
Analyzing what’s missing from the data is just as important as examining what’s present.
Testing Edge Cases and Rare Scenarios
To strengthen model reliability, QA teams must proactively address edge cases. Domain experts are particularly skilled at identifying these scenarios before they impact users.
Long-tail coverage analysis helps pinpoint rare but critical categories that may be underrepresented. These categories can be expanded through synthetic data generation or external sources. Using AI for production-like test data creation can further streamline this process while maintaining privacy compliance. The goal isn’t to equally represent every scenario but to ensure the model can handle rare, high-impact situations effectively.
Adversarial injection is another valuable technique. This involves adding challenging samples to the training data, such as typos, mixed-language inputs, boundary values, and common misphrasings paired with their correct versions. Including error-correction examples helps the model handle imperfect inputs more effectively.
"Red-teaming is one of the most effective ways to find blind spots in machine learning datasets. It's about simulating how things can go wrong - and fixing them before your users find out the hard way."
- Ian Goodfellow, Research Scientist, DeepMind
Instead of relying solely on broad datasets, QA teams can create targeted datasets to address specific failure points, such as "Query Hallucinations" or unique customer scenarios. Start with a small "seed" dataset of examples for these edge cases and expand it using data synthesis tools. Domain experts should also author "must-pass" scenarios with explicit criteria to serve as benchmarks for reliability.
To evaluate with confidence, QA teams should aim for about 246 samples per scenario or data slice, ensuring a 95% confidence level with a 5% margin of error. Using Generative Annotation Assistants (GAAs) can speed up annotation by 30%, while adversarial methods can improve model fooling rates by up to 5x.
Platforms like Ranger (https://ranger.net) support QA teams by combining AI-driven testing with human oversight, helping to catch edge cases and unusual scenarios that automated systems might overlook.
Testing AI Models for Performance
Performance testing is an ongoing process designed to catch issues before they impact users. By using quality data and thorough testing, QA professionals ensure AI models perform well in real-world conditions.
Identifying Overfitting and Underfitting
Overfitting occurs when a model becomes too focused on its training data, excelling in controlled environments but stumbling with new scenarios. Underfitting, on the other hand, happens when a model struggles to make accurate predictions even with familiar data, often due to oversimplified design or poor data quality.
QA teams detect overfitting by analyzing a generalization curve - if training loss drops while validation loss rises or diverges, it's a clear signal of overfitting. To address this, datasets are typically split into three parts:
- Training: Used to build the model.
- Validation: Used for initial testing and fine-tuning.
- Test: Reserved for unbiased final evaluations.
"Data trumps all. The quality and size of the dataset matters much more than which shiny algorithm you use to build your model." - Google Machine Learning Crash Course
Cross-validation further ensures consistent performance by testing the model across different data subsets. Interestingly, about 80% of the time in machine learning projects is spent preparing and transforming data, which has a direct impact on whether models overfit or underfit.
Once a model generalizes well, QA teams move on to functional and regression testing to ensure its reliability.
Running Functional and Regression Tests
Functional testing checks if a model behaves as expected across various scenarios, while regression testing ensures updates or retraining don’t disrupt existing functionality. Both rely on a golden dataset - a carefully curated set of input-output examples that cover typical cases, edge cases (like handling unusual inputs), and adversarial scenarios.
To evaluate model responses, QA teams use techniques like:
- Semantic similarity (e.g., cosine similarity).
- LLM-as-a-judge, where a more advanced model assesses outputs.
- Statistical thresholds to measure performance.
An example of success: In early 2026, Notion’s product team boosted their issue-resolution rate from 3 fixes per day to 30, a 10x improvement, by adopting systematic evaluation and regression testing workflows with Braintrust.
"Regression testing ensures that changes to code don't mess things up... The goal is to avoid breaking old features or reintroducing known bugs." - Elena Samuylova, CEO, Evidently AI
To streamline this process, QA teams often integrate regression test suites into AI-enhanced CI/CD pipelines. These suites automatically block deployments if quality scores dip below predefined thresholds. For subjective qualities like tone or sentiment, teams may set acceptable fail rates (e.g., 10%) rather than requiring perfection. Typically, regression testing starts with 25 to 50 high-quality test cases, expanding as new issues arise in production.
Debugging is made easier with tracing, which captures prompts, retrieved documents, and raw outputs, providing context for failures. Functional tests should also include "implicitly adversarial" queries - seemingly innocent questions that might provoke unintended or policy-violating responses.
Testing Under Real Conditions
AI models must demonstrate reliability under real-world conditions. A crawl/walk/run framework is particularly effective for voice and real-time systems:
- Crawl: Use clean, synthetic audio and single-turn requests to test basic reasoning and tool usage.
- Walk: Introduce production-style audio with noise, compression, and other imperfections to test robustness.
- Run: Conduct multi-turn simulations to evaluate the system’s ability to maintain context and handle evolving goals.
User simulators - advanced models acting as realistic or even adversarial users - are valuable for testing multi-turn dialogues. For AI agents like coding assistants, testing in sandboxed environments (e.g., browsers, desktops, or repositories) verifies whether the model achieves desired outcomes, such as correct database updates or functional code patches.
"Evals are what turn a voice demo into something people can rely on. The gap between 'seems fine' and 'works every day' is almost always evals." - Minhajul Hoque, OpenAI
Online evaluation - scoring live production data - detects "outcome drift", where business KPIs shift despite stable offline scores. Advanced LLM judges, like GPT-4, achieve over 80% agreement with human preferences, comparable to the agreement rate between two human evaluators. Teams that prioritize robust evaluations can accelerate AI product deployment by 5–10×, catching issues early.
Platforms like Ranger (https://ranger.net) combine automated testing with human oversight, helping QA teams spot problems that automated tools might miss. This balanced approach underscores the critical role of QA in building reliable AI systems that perform well in unpredictable, real-world scenarios.
Setting Up Continuous Monitoring and Retraining
Once QA teams have tackled testing and data preparation, the next step is ensuring your AI model keeps performing well over time. AI models need ongoing checks and updates. Why? Because user behaviors evolve, and new edge cases pop up regularly. QA teams are crucial here, spotting shifts early and maintaining model reliability through constant monitoring and retraining.
Creating Monitoring Systems for AI Models
To monitor effectively, you need to track four key areas: model performance, data drift, operational metrics, and business KPIs. Each of these reveals specific issues that could affect your model.
QA teams focus on spotting data, concept, and label drift. They use a mix of real-time metrics (like model confidence levels and out-of-vocabulary rates) and delayed evaluations based on ground-truth data.
Slice-level analysis is a must. It digs into specific segments - like performance by region, language, or high-value users - so you can catch problems that overall metrics might miss. For instance, in customer-facing AI systems like chatbots, keeping the p95 latency (the time it takes to respond to 95% of requests) under 1.0 seconds is often the goal to ensure a smooth user experience.
Take this example: In October 2025, Samuel Patel, an AI deployment lead, shared insights about a customer-support assistant managing 18,000 chats weekly. By monitoring a 2.4% hallucination rate and a p95 latency of 1.1 seconds, his team pinpointed areas needing improvement. After reducing hallucinations to under 1% and bringing latency below 1.0 seconds, they cut human agent escalations by 28% and saved about 40 agent-hours daily.
These monitoring systems pave the way for timely model retraining.
Establishing Retraining Triggers and Protocols
Retraining should be based on clear, measurable triggers. QA teams set up indicators to know when updates are necessary. These can include sustained KPI deviations, detected data drift (using tests like Kolmogorov-Smirnov or Chi-square), or confirmed changes in taxonomy. Typical triggers fall into these categories:
- Threshold-based: When performance drops below a specific KPI.
- Time-based: Scheduled retraining (e.g., weekly or monthly).
- Data volume-based: A significant influx of new data.
- On-demand: Manual retraining triggered by a review.
Before deploying retrained models, QA teams use a structured test plan and rely on shadow testing (running the new model alongside the production model) or canary rollouts (testing on a small portion of traffic) to ensure the updates meet performance expectations. They also maintain "golden datasets" with edge cases to run automated regression tests during updates , often developed from comprehensive test scenarios. Tools like automated scorers measure semantic similarity between new outputs and reference answers. A similarity score below 0.8 often flags potential issues.
| Retraining Trigger | Description |
|---|---|
| Interval-based | Scheduled weekly, monthly, or yearly updates |
| Performance-based | Triggered by metric drops below a set threshold |
| Data-change-based | Activated by shifts in data distribution |
| On-demand | Manually triggered after ad-hoc reviews |
Human-in-the-loop systems are also vital. These protocols escalate low-confidence predictions or tricky edge cases to human experts for review and labeling. This keeps automated scoring systems closely aligned with human quality standards.
"Deploying a machine learning model isn't the finish line - it's the starting point of a new, unpredictable phase." - HumanSignal
Building QA Team Skills in AI Testing
QA professionals bring their expertise in identifying edge cases, verifying quality, and ensuring user protection to the world of AI testing. However, the focus shifts from just code correctness to areas like data quality, model accuracy, and fairness.
Training QA Teams for AI Testing
Developing AI testing skills involves a step-by-step approach:
- Stage 1 – Foundations: Start by understanding how models handle data, including splitting it into training, validation, and test sets. Learn key evaluation metrics like precision, recall, and F1-score.
- Stage 2 – Intermediate Skills: Move on to detecting bias through subgroup testing and running adversarial tests to uncover security vulnerabilities. Explore fairness tools like Fairlearn and IBM AI Fairness 360 to deepen your knowledge.
- Stage 3 – Advanced Topics: Tackle challenges specific to large language models, such as prompt injection, hallucinations, and toxic outputs.
For structured learning, certifications like ISTQB AI Testing (CT-AI) and ISTQB Testing with Generative AI (CT-GenAI) can guide your team. Alternatively, self-guided resources such as the Google ML Crash Course and scikit-learn documentation provide excellent starting points. Embrace probabilistic testing methods to address the variability in model outputs.
Beyond technical know-how, building strong collaborations with data science teams is essential.
Improving Collaboration Between QA and Data Science Teams
Once QA teams are equipped with both foundational and advanced AI testing skills, working closely with data science teams becomes crucial for better results. Collaboration starts with a shared understanding of how the model was trained, including the data sources used and its inherent limitations. This shared knowledge allows QA teams to design more effective tests and catch issues that might otherwise slip through the cracks.
A useful approach is creating "Golden Datasets", which consist of realistic customer queries paired with expert-verified answers (about 100–150 pairs). These datasets help benchmark the model's performance and monitor drift over time. When testing reveals edge cases or failure modes, QA teams should communicate these findings directly to the data science team, enabling them to adjust and retrain the model as needed.
Defining success metrics together is another key step. Accuracy alone isn’t enough; both teams need to agree on acceptable levels of risk, confidence thresholds, and strategies for addressing various types of failures. Regular cross-functional meetings can help maintain alignment as models evolve and new challenges arise. This collaborative effort ensures the delivery of robust and reliable AI systems.
Conclusion
Quality assurance (QA) plays a critical role throughout the AI model lifecycle. Whether it’s ensuring data quality before training begins or monitoring for issues like drift in production, QA professionals help maintain the accuracy, fairness, and reliability of models. Their ability to identify edge cases and prioritize user safety is invaluable.
"10,000 high-quality pairs outperform 100,000 mediocre ones every time." - Tao An
The results speak for themselves: quality data can boost model performance by 30–50%, while specialized QA strategies have cut regression testing time in half in practical applications. These improvements highlight why rigorous QA practices should be implemented as early as possible.
Developing your team’s understanding of AI is key. This includes structured learning paths that cover everything from basic metrics like precision and recall to more advanced topics such as adversarial testing and bias detection. Partner with data science teams to establish meaningful metrics that go beyond simple accuracy. Additionally, set up automated systems to detect concept drift - when the relationship between inputs and outputs shifts over time - to avoid unnoticed performance declines.
To bring these efforts to life, reliable tools are essential. For example, tools like Ranger (https://ranger.net) provide AI-driven testing infrastructure combined with human oversight. With features like automated test creation, easy maintenance, and real-time testing updates, Ranger integrates seamlessly with platforms like Slack and GitHub. These capabilities allow your team to focus on advanced techniques that strengthen AI model reliability. Combining the right expertise with effective tools ensures your models can evolve and improve, rather than getting stuck in a cycle of constant optimization.
FAQs
What should QA test first when an AI model is failing?
When an AI model doesn't perform as expected, the first step in QA is to identify and analyze the specific bugs or failure modes. This can be done through targeted tests, such as structured prompts or unit tests, which help isolate the underlying problems. By zeroing in on these root causes, you can address the issues effectively and ensure the fixes lead to meaningful improvements in the model's performance.
How can we prove our training data isn’t biased?
Ensuring training data is free from bias takes a mix of strategies. One effective approach is using stress-testing datasets. These datasets help spot any hidden biases or gaps in the data by pushing it to its limits. Another key method involves applying human-in-the-loop auditing frameworks, where human reviewers actively assess and refine the data to promote fairness.
Golden datasets - carefully curated, neutral benchmarks - can also be used to evaluate whether the training data aligns with fairness standards. Additionally, techniques like adversarial testing, bias detection, and drift analysis play a crucial role in identifying and addressing any problematic patterns in the data.
By combining these tools with transparent evaluation processes and human oversight, it becomes possible to create training data that is more balanced and equitable.
When should we retrain the model in production?
When data patterns change, performance declines, or monitoring flags the need for updates, it's time to retrain the model in production. Keeping an eye on these factors through continuous monitoring is crucial to maintain the model's accuracy and reliability over time.
Related Blog Posts
Stop babysitting your coding agents. Use Ranger
More signals, less noise, faster launches
Let Ranger be your guide to sustainable QA testing.

.png)