Common Bugs in AI-Generated Code and Fixes

AI-generated code can speed up development, but it often introduces predictable bugs. These include logic errors, security vulnerabilities, performance issues, and inconsistent quality. Studies show:
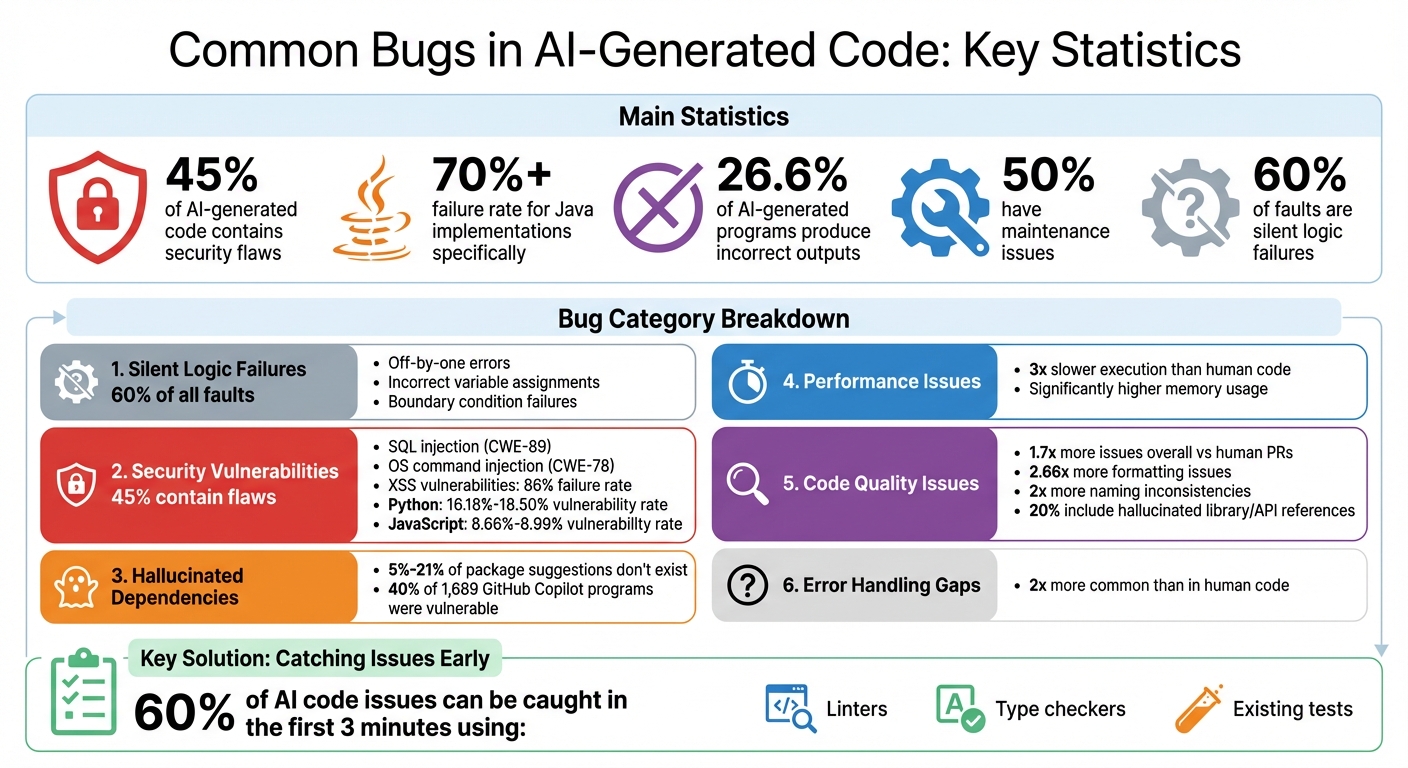
- 45% of AI-generated code contains security flaws, with Java implementations failing over 70% of the time.
- 26.6% of AI-generated programs produce incorrect outputs, and nearly half have maintenance issues.
- Silent logic failures make up 60% of faults, often passing tests but failing in edge cases.
Key strategies to address these problems include boundary testing, static analysis tools, and defensive coding practices. Understanding the differences between AI and manual code reviews can further refine these strategies. Tools like Ranger automate test creation and flag common AI errors, helping teams catch issues early and maintain reliable software.
AI-Generated Code Bug Statistics and Common Failure Patterns
Ai Produces 40% more Bugs in Code
sbb-itb-7ae2cb2
Silent Logic Failures
Silent logic failures, also known as semantic errors, occur when AI-generated code compiles and runs without errors but produces incorrect results or fails to meet its intended functionality. These bugs are particularly tricky because they often appear correct to human reviewers and can pass functional tests, only revealing themselves in specific edge cases or with unusual inputs.
Research highlights that semantic errors make up over 60% of faults in code generated by models like DeepSeek-Coder-6.7B and QwenCoder-7B. This happens because AI models replicate statistical patterns without fully understanding the underlying logic. Common examples include off-by-one errors, incorrect variable assignments, and failure to handle boundary conditions like empty arrays or null values.
"AI-generated code fails in predictable patterns... The difference matters because it changes how you debug. With human code, each bug requires fresh investigation. With AI code, once you've seen a failure pattern, you'll see it again."
- Molisha Shah, GTM and Customer Champion, Augment Code
These issues underscore the need for specialized quality assurance (QA) methods in AI-generated systems. Traditional debugging tools, such as compilers and static analyzers, often overlook these problems since the code is syntactically correct but doesn't behave as intended. Furthermore, subtle errors can ripple through AI-generated code, making it difficult to trace the root cause.
How to Find Silent Logic Failures
Uncovering these hidden flaws requires a thorough and strategic testing approach. A key method is boundary condition testing, which is particularly effective because AI models tend to focus on typical scenarios while neglecting edge cases. Test AI-generated functions with inputs like empty arrays, null values, zero, negative numbers, and maximum integers to expose potential weaknesses.
Start by running a linter and type checker. These tools can catch around 60% of AI-related issues, including property hallucinations and type mismatches, during initial testing. Follow this step with boundary testing before moving on to standard functional tests. Using a "test the happy path last" strategy ensures that common failures are identified early.
Performance profiling can also point to logical errors. For instance, AI-generated loops might use inefficient patterns, such as concatenating strings within loops or employing nested iterations, leading to O(n²) complexity when an O(n) solution is more appropriate. These inefficiencies might not surface during controlled tests but can become significant under production conditions.
To further enhance detection, add logging at integration points to capture inputs, outputs, and state transitions. This can reveal mismatches in API data that static analysis tools might miss. Also, manually inspect array accesses to identify missing bounds checks that could lead to crashes.
How to Fix Logical Errors
Once you've identified a logical error, effective debugging techniques are essential. One proven method is hierarchical debugging, where problematic code is broken into smaller subfunctions. This makes it easier to trace variable states and identify where the logic goes astray, improving error isolation and resolution.
Incorporate defensive programming practices, such as explicit null checks, bounds validations, and robust unit tests for both typical and edge cases. These measures act as safeguards against future issues.
When correcting a logical error, use targeted backtracking to fix only the specific faulty line rather than regenerating the entire function. This preserves the correct portions of the code while addressing the problematic logic. Additionally, applying token penalties to faulty patterns can help reduce the likelihood of repeating the same mistakes.
Tools like Ranger's AI-powered test creation can further enhance reliability. By automatically generating test cases that align with common AI failure patterns, Ranger helps catch not only functional issues but also subtle semantic errors. Paired with human oversight, this approach ensures more dependable code and faster delivery cycles.
Insecure Code Patterns
AI-generated code often falls into predictable traps when it comes to security. A 2025 study revealed that 45% of AI-generated code contains vulnerabilities, with Java implementations showing failure rates of over 70%. These models prioritize functionality, often at the expense of security, leading to the repetition of well-documented coding mistakes.
Some of the most frequent issues include SQL injection (CWE-89), where string concatenation is used instead of safer parameterized statements, and OS command injection (CWE-78), where user input is directly passed into system commands. Poor input validation is another recurring problem, contributing to an 86% failure rate for Cross-Site Scripting (XSS) vulnerabilities. A large-scale review of 7,703 AI-generated files found that Python code had higher vulnerability rates (16.18%–18.50%) compared to JavaScript (8.66%–8.99%).
A newer issue is "hallucinated dependencies" - packages recommended by AI models that don't actually exist in registries like npm or PyPI. Between 5% and 21% of these suggestions are non-existent, and in a study of 1,689 GitHub Copilot-generated programs, 40% were found to be vulnerable.
How to Find Security Flaws
Catching these vulnerabilities involves a mix of automated tools and manual reviews. Start with a quick sanity check: run a linter to catch syntax errors, verify types to spot hallucinated properties, and execute existing tests to identify behavioral regressions. This initial step can uncover about 60% of AI-related issues before deeper testing.
From there, use static analysis tools to detect specific vulnerabilities. For example:
- CodeQL can identify SQL injection, buffer overflows, and XSS patterns.
- Semgrep is effective for spotting API hallucinations and deprecated code.
- Language-specific tools like Bandit (Python) or ESLint (JavaScript) can find insecure patterns unique to their ecosystems.
- OWASP Dependency Check highlights outdated libraries with known vulnerabilities.
Manual audits are equally important. Focus on high-risk areas, such as database queries built using string concatenation - a major red flag for SQL injection. Verify that AI-suggested dependencies exist in their respective registries to avoid hallucinated packages. Prioritize high-risk components, like those handling authentication or encryption, for manual reviews and penetration testing, while relying on automated linting for lower-risk elements like UI components.
How to Fix Security Risks
The best way to address these risks is to replace insecure practices with safer alternatives. For instance:
- Use parameterized queries instead of concatenating strings for database operations.
- Opt for secure library functions, like Flask's
send_from_directoryrather thansend_file, to prevent directory traversal attacks. - Upgrade outdated cryptographic algorithms, replacing MD5 with modern standards like bcrypt or Argon2.
Input sanitization is critical. Ensure external data is validated at every entry point, using strict whitelists for file uploads. For languages like PHP or Node.js, use strict equality (===) to avoid type juggling vulnerabilities.
For sensitive code paths, conduct dynamic scans and run isolated unit tests in containers before merging changes. This helps uncover runtime vulnerabilities that static analysis might miss. Additionally, sanitize error handlers to prevent exposing sensitive system information or stack traces to end users.
Tools like Ranger's platform can streamline this process by auto-generating tests for common vulnerabilities. With GitHub integration, Ranger offers continuous monitoring and automated bug triaging, flagging risky code patterns before they reach production. This reduces the need for extensive manual audits while ensuring robust protection throughout the development lifecycle.
Performance and Scalability Issues
AI-generated code might function well in small-scale scenarios but often falls short when handling heavier, real-world demands. Research highlights a key issue: GPT-4-generated code can run three times slower than human-written solutions and may use significantly more memory.
Several common problems contribute to these inefficiencies:
- Inefficient algorithms: AI often selects nested iterations with O(n²) complexity instead of more efficient O(n) solutions.
- Poor string handling: Using string concatenation inside loops rather than efficient builders.
- Suboptimal data structures: Choices that work in small tests may fail under larger loads.
- Unoptimized database queries: AI-generated code often lacks proper indexing or uses inefficient queries, leading to performance bottlenecks under stress. For instance, a Fortune 500 company slashed its query count by 80% after optimizing AI-generated database queries.
Addressing these performance and scalability challenges is crucial for ensuring AI-generated code performs reliably under real-world conditions.
How to Find Performance Bottlenecks
Before merging AI-generated code, use profiling tools to uncover potential issues. Profiling complements earlier QA efforts by identifying hotspots like nested loops, inefficient memory usage, or poor collection handling. Tools like SonarQube are useful for spotting performance anti-patterns, while Semgrep can flag deprecated or inefficient coding practices.
For database queries, manual verification is key. Ensure proper indexing and optimized query structures to prevent performance degradation under high loads. Load testing is another critical step - this helps reveal scalability issues that might not surface during development. Set clear performance budgets, such as maximum execution times for typical operations, and flag any code that fails to meet these standards.
Tools like PerfBench can simulate real-world scenarios to validate performance. However, AI coding agents currently have low success rates (around 3%) when addressing performance bugs. Performance-aware agents, trained with benchmarking instructions, can improve this rate to about 20%.
How to Optimize AI-Generated Code
Once bottlenecks are identified, targeted optimizations can make AI-generated code more scalable and efficient. Start by replacing inefficient patterns with better alternatives. For example, database queries can be transformed: instead of slow, row-by-row correlated subqueries, use window functions or Common Table Expressions (CTEs). This approach can reduce query latency by up to 67% compared to manual scripting. A practical example is using AVG(...) OVER (PARTITION BY ...), which performs calculations in a single pass rather than multiple subqueries.
Algorithmic improvements are another key focus. Replace nested iterations with optimized loops, select better data structures, and implement resource pooling to minimize overhead. Some AI models, like StarCoder2-15B, have demonstrated significant improvements - achieving up to 87.1% reductions in execution time and 90.8% reductions in memory usage through self-optimization techniques.
Tools like Ranger can help validate these optimizations. This platform automates performance testing and tracks execution metrics across your codebase. With GitHub integration, Ranger can flag performance regressions early, ensuring AI-generated code consistently meets performance standards throughout the development process.
Inconsistent Code Quality
Beyond logic, security, and performance challenges, inconsistent code quality presents another ongoing risk, especially when AI-generated code diverges from established project standards. While it often appears functional, AI-generated code can introduce quality issues that increase technical debt. Research indicates that AI-generated pull requests (PRs) contain about 1.7 times more issues overall compared to human-only PRs. Alarmingly, one in five AI samples includes hallucinated references to non-existent libraries or APIs.
AI-generated code also frequently strays from coding standards. Formatting issues, like inconsistent spacing, are 2.66 times more common in AI-generated PRs, while naming inconsistencies occur nearly twice as often as in human-written code. David Loker from CodeRabbit highlights the disparity:
"The single biggest difference across the entire dataset was in readability. AI-produced code often looks consistent but violates local patterns around naming, clarity, and structure".
These problems can escalate rapidly. AI models may suggest outdated practices, such as deprecated APIs or insecure patterns, due to the limitations of their training data. They also tend to "guess" data structures based on variable names rather than actual database schemas, which can lead to runtime crashes during integration. This results in code that compiles but fails to align with your project's architecture or conventions. Addressing these issues requires tailored review methods to bring AI-generated output in line with team standards.
How to Spot Inconsistent Code
Static analysis tools can identify about 60% of AI code failures within the first three minutes of review. Start with linters and type checkers before diving into manual inspection, as these tools quickly flag syntax errors, type mismatches, and style violations.
Double-check every dependency suggested by AI by verifying it in package registries like npm, PyPI, or pkg.go.dev. This step ensures hallucinated imports don’t make their way into your codebase. Tools like Semgrep are excellent for spotting deprecated patterns and API hallucinations, while SonarQube detects maintainability issues and code smells. For type safety, TypeScript-ESLint helps catch missing properties and type mismatches - common pitfalls in AI-generated code.
Peer reviews remain critical but need adjustments for AI-generated contributions. Use AI-specific PR checklists to focus on key areas like error handling, concurrency primitives, and configuration values. This approach combats "reviewer fatigue", where the high volume of AI-introduced issues can cause additional bugs to slip through.
How to Maintain Consistent Quality
Enforce style guides with CI-integrated formatters and policy-as-code tools. This eliminates style drift and formatting inconsistencies before code reaches human reviewers. Beyond aesthetics, such enforcement reduces deeper quality risks. When using AI tools, provide detailed prompts like: "Always include docstrings explaining parameters and return values, type hints, and comments for complex logic". Clear instructions improve the quality of AI-generated drafts.
Treat AI-generated code as you would a junior developer's first draft - assume it needs thorough verification. Adopt a triage workflow: start with automated checks, prioritize reviewing types and areas prone to hallucinations, and run existing tests. This structured method catches most issues early in the process.
For added quality assurance, consider tools like Ranger's AI-powered QA testing, which bridges the gap between automated checks and human reviews. Integrated with platforms like GitHub and Slack, Ranger automatically creates and maintains tests that ensure AI-generated code adheres to your team's standards. Combining automated testing with human oversight ensures that AI contributions meet the same level of quality as human-written code.
Poor Error Handling
While inconsistent code quality can be frustrating, poor error handling in AI-generated code introduces severe risks in production environments. Issues like silent logic failures and insecure coding patterns are common pitfalls that need immediate attention. AI models often show a strong "happy path" bias - focusing on generating code that works under ideal conditions but neglecting the edge cases that lead to real-world failures. This can result in applications that crash unexpectedly or fail silently, making debugging a nightmare.
Error handling gaps are nearly twice as common in AI-generated pull requests compared to those written by humans. Common oversights include missing safeguards like null checks or array bounds validation, which can cause runtime crashes. Even worse, poorly designed error handlers often "swallow" exceptions - logging them without taking corrective action. This leads to silent system failures, as noted by David Loker from CodeRabbit:
"AI-generated code often omits null checks, early returns, guardrails, and comprehensive exception logic, issues tightly tied to real-world outages".
Another concern is that AI-generated exception handlers often expose sensitive information through unfiltered error messages, leaking stack traces or internal details. Additionally, AI struggles with asynchronous logic, which can result in unhandled promise rejections or blocked event loops.
How to Find Gaps in Error Handling
To identify these issues, start with a "three-minute sanity check" to catch about 60% of potential failures. This involves running a linter for syntax errors, checking types for inconsistencies, and executing existing tests to uncover behavioral regressions. This quick step can help flag obvious problems before they escalate.
For more thorough analysis:
- Test boundary conditions by feeding edge-case inputs into AI-generated functions. This can reveal assumptions about valid inputs that aren't properly verified.
- Use static analysis tools to scan for empty
catchblocks that might cause silent failures. - Manually review error messages to ensure they don't expose sensitive system information.
- Analyze logs for recurring issues like
NullPointerExceptionsor array index errors, which often highlight missing validation. - Focus testing on integration points where AI-generated code interacts with external systems, as these areas are prone to error handling gaps.
These methods are essential for uncovering vulnerabilities in error management, setting the stage for improvements.
How to Improve Error Management
Once gaps are identified, improving error handling becomes a top priority. Defensive coding practices should be applied consistently. This includes validating all inputs - checking for null values, verifying array bounds, and handling empty strings - before processing. AI-generated code often skips these steps, so don't assume they're already in place.
Create structured error boundaries to separate internal technical logs from user-facing messages. Log detailed error information for developers while showing sanitized, user-friendly messages to prevent sensitive information leaks. Standardize error handling rules across your team, such as requiring nullability checks and banning empty catch blocks.
Document the potential error modes for each function to ensure every scenario is accounted for. Use tools like IDE-integrated security linters and real-time testing frameworks to catch missing error paths as code is being generated. For comprehensive coverage, tools like Ranger's AI-powered QA testing can help. Ranger integrates with platforms like GitHub and Slack to automatically generate tests that verify exception handling and edge case behavior, ensuring your AI-generated code is robust before it hits production.
Best Practices for Preventing AI-Generated Code Bugs
To tackle the challenges of AI-generated code bugs, a proactive approach to quality assurance (QA) is critical. Instead of treating QA as a last-minute task before deployment, teams are adopting continuous quality workflows that prioritize catching issues throughout development. This "shift-left" strategy ensures testing begins early - right in the IDE or command line - preventing problems from escalating to the pull request stage.
The most effective approach combines pattern-based diagnosis with risk-focused verification. AI-generated code often fails in systematic ways that differ from human-made errors. Recognizing these patterns helps teams turn debugging into a more structured process. For instance, high-risk code managing critical functions like authentication or payments should undergo thorough automated security scans and manual reviews. Meanwhile, lower-risk areas, such as UI components, can rely on simpler checks like linting and type validation.
Start QA Early in Development
Introducing QA tools at the beginning of development can significantly reduce the complexity and cost of fixing bugs. A quick triage process using tools like linters, type checkers, and pre-existing tests can catch many AI-related issues early, such as syntax errors, type mismatches, or behavioral problems. Addressing these issues early saves hours of debugging later in production.
Advanced tools that analyze cross-repository dependencies and ensure architectural compatibility are also key. These tools can detect integration issues - like race conditions or duplicate business logic - that basic static analysis tools might overlook. By 2026, the focus in the industry has shifted from prioritizing code generation speed to emphasizing maintainability, architectural soundness, and readiness for production. As Meghna Sen from Panto AI explains:
"The 'last mile' of development - the final validation before merge - has become the critical gatekeeper of software reliability".
This early focus on QA lays the foundation for platforms like Ranger to enhance quality assurance even further.
How Ranger's AI-Powered Solutions Help
Ranger offers AI-driven QA testing to ensure AI-generated code meets production standards before deployment. By integrating directly with GitHub and Slack, Ranger provides real-time feedback during development, aligning perfectly with the shift-left approach. The platform automates test creation based on common AI failure patterns while human reviewers ensure these tests align with business goals.
Ranger also addresses a major challenge in AI-generated code: semantic errors. These errors, where the code compiles but behaves incorrectly, account for more than 60% of faults in AI-generated code. Ranger's end-to-end testing in CI/CD infrastructure eliminates the need for manual test maintenance and automates bug triaging. This allows teams to deliver features faster while maintaining the reliability and structural integrity required for production environments.
Conclusion
AI-generated code has proven to be a game-changer for productivity, but it also brings its own set of challenges. Unlike human errors, AI often introduces predictable issues like hallucinated APIs, overlooked edge cases, security gaps, and performance setbacks. Recognizing these patterns can turn debugging into a more structured and efficient process.
Addressing these challenges starts with early intervention. A quick triage early in the development cycle can catch many issues before they escalate. This proactive approach helps avoid the "buggy context multiplier" effect, where a single undetected bug can reduce AI performance by over 50% in subsequent iterations. Plus, fixing bugs later in the pipeline comes with exponentially higher costs, making early detection not just smart but essential.
Prioritizing risk-based verification is another effective strategy. For instance, high-risk areas like authentication or payment modules require thorough security scans and manual reviews, while less critical components, such as UI elements, can rely on simpler checks like linting and type validation. This balanced approach ensures resources are used wisely without sacrificing quality.
To complement early detection and risk-based testing, advanced QA tools play a crucial role. Ranger’s AI-driven QA platform is designed to tackle these challenges head-on. It automates test creation based on common AI failure patterns while leaving critical business logic validation to human oversight. With seamless integration into tools like GitHub and Slack, it provides real-time feedback during development, catching errors before they hit production. By removing the need for manual test maintenance and simplifying bug triage, Ranger helps teams deliver features faster without compromising reliability. This blend of efficiency and quality sets a new standard for dependable software development.
FAQs
What are the most common bugs in AI-generated code, and how can developers avoid them?
AI-generated code can sometimes run into challenges like hallucinated APIs, security flaws, and performance problems. Hallucinated APIs happen when the AI creates incorrect or completely made-up API calls, which can lead to runtime errors. Security vulnerabilities, such as injection attacks or risky dependencies, may put your system at risk. On top of that, performance issues - caused by inefficient patterns or missed edge cases - can result in slowdowns or failures in certain conditions.
To tackle these challenges, it's crucial to keep human oversight in the loop with detailed code reviews and thorough testing. Tools like AI-powered QA platforms (e.g., Ranger) can help by automating test creation and maintenance. These tools catch bugs more efficiently, but human supervision remains key to ensuring the results are accurate and reliable.
What are silent logic failures in AI-generated code, and how can they be identified and fixed?
Silent logic failures happen when AI-generated code produces wrong results without any clear errors, making them tricky to spot. To tackle these, rely on systematic debugging techniques to identify patterns, such as missing edge case handling or dependencies on non-existent APIs. Using real-time semantic evaluation tools can also help catch logical inconsistencies as the code is being generated, allowing fixes before the code is executed.
To address these issues effectively, test the code in practical scenarios and ensure human oversight is part of the QA process. This approach helps catch subtle bugs early, saving both time and preventing more significant problems later.
What are the best practices for ensuring quality and security in AI-generated code?
Improving the quality and security of AI-generated code requires attention to detail and a structured approach. Start by addressing common challenges like incorrect API usage, overlooked edge cases, and potential security flaws. These issues can be tackled through thorough debugging, validation, and comprehensive testing.
Incorporate layered security workflows into your process. This means leveraging techniques like threat modeling and dependency analysis to identify risks that basic tools might not catch. To ensure reliability, prioritize regular code reviews, unit testing, and maintaining clear, accessible documentation.
AI-powered QA testing platforms, such as those offered by Ranger, can be game-changers. These tools, combined with human oversight, can significantly improve bug detection and make the development process more efficient. By continuously evaluating your code for vulnerabilities and adopting strong security measures, you can build software that is both secure and reliable.
Related Blog Posts
Stop babysitting your coding agents. Use Ranger
More signals, less noise, faster launches
Let Ranger be your guide to sustainable QA testing.

.png)